
HTTP之旅
HTTP简介
当我们接触一个 Web 应用程序时,首先接触的应用层协议是 超文本传输协议(HyperText Transfer Protocol,HTTP)。
HTTP由两个程序实现:一个客户端、一个服务器。
其连接模型为:
- 客户端向服务器发起 请求(request)
- 服务器收到请求后,进行 响应(response),返回客户端需要的内容
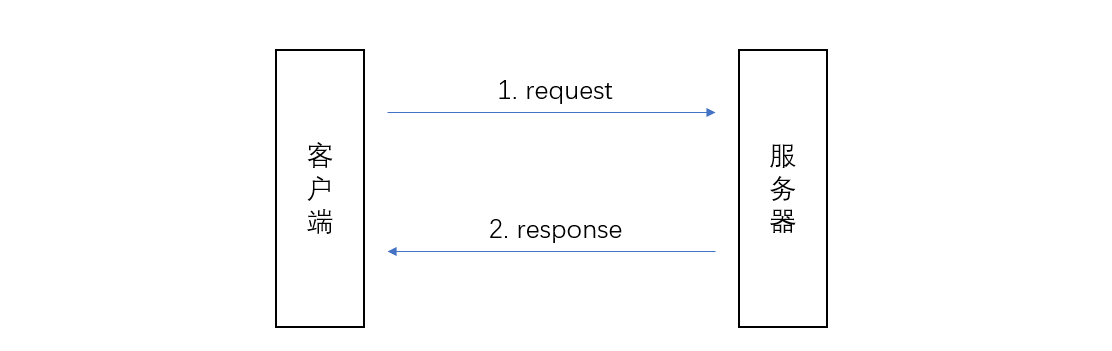
与 HTTP 有关的概念
1. web 对象
一般来说,一个 Web page(页面)是由很多对象组成的。对象可以是 html、图片、视频,甚至是Java程序。例如,当我们访问 https://www.google.com ,这个 Web page 是由 Google 提供的一个基本 html 页面和搜索框上面大大的 logo 图片(以及其他对象)组成。
这个 html 页面是一个对象(通常为index.html),其中的 logo 图片也是一个对象。这些对象都存储在服务器上面。
实际上对象一般都可以通过 URL 寻址,比如谷歌首页的Logo图片,其URL地址是 https://www.google.com/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png
HTTP 定义了客户端如何向服务器请求 Web page。
HTTP 使用 TCP 作为支撑运输协议,所以不用担心请求的过程数据在中途丢失或出错的问题。
2. 无状态协议
我们可能注意到,我们使用浏览器打开Google.com,然后新建一个标签页,又重新打开一次,Google 的页面还是会又一次地显示出来,不存在服务器之前已经给你发过了所以不再发这种事。因此我们说 HTTP 是 无状态协议(stateless protocol) 。
3. 非持续连接和持续连接
如果一个客户端与服务器的 每一个 请求/响应 对,分别由单独的 TCP 连接发送,这样的 Web 应用程序称为 非持续连接(non-persistent connection)。假设在一个由 1 个 index.html 和 10 张 jpg 图片组成的 Web page 中传输,则会建立 11 个 TCP 连接。
反之,如果同一个客户端的所有请求及服务器对它的响应经过相同的 TCP 连接发送,称为 持续连接(persistent connection)。这样在上述例子中只需要建立 1 个 TCP 连接。
HTTP/1.0 协议使用非持久连接,即在非持久连接下,一个tcp连接只传输一个 Web 对象;HTTP/1.1 默认使用持久连接(当然,你也可以配置成使用非持久连接)。
HTTP request 报文
HTTP request报文结构如下:
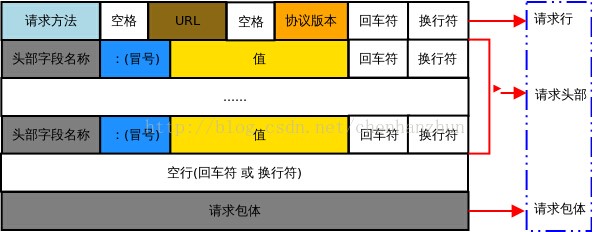
一个简单的 HTTP 报文如下:
GET /www.zsc.edu.cn/index.html HTTP /1.1
Accept-Language:zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7
Host:www.zsc.edu.cn
Connection: close
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36请求行
GET /www.zsc.edu.cn/index.html HTTP /1.1HTTP 报文的第一行称为 请求行(request line) ,包含三部分:请求方法、请求地址、协议版本。之间用空格隔开。
GET 说明采用了 GET 方法, HTTP协议中,有GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT 等方法,其中最常用的是 GET 和 POST, GET用于获取内容, POST常用于表单提交。其后接着的是请求的URL地址以及采用的 HTTP 协议版本,这里是 1.1。
不是向服务器提交表单就一定要用 POST,比如我们在某网站的表单的name填 hello , age 填 18,然后点击确定,浏览器可能会构造一个类似于 www.somesite.com/select?name=hello&age=18 这样的URL传递给服务器。服务器解析这种 URL 就知道你填的是什么了。当然,这种情况不适合输入账号和密码。
首部行
Accept-Language:zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7
Host:www.zsc.edu.cn
Connection: close
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36请求行后面的几行称为 首部行(header line),用来提供一些额外的信息。
request常见首部
| 首部 | 解释 |
|---|---|
| Accept | 客户端能够处理的媒体类型 |
| Accept-Charset | 客户端能够支持的字符集 |
| Accept-Encoding | 客户端能够支持的内容编码 |
| Accept-Language | 客户端能够支持的自然语言集 |
| Authorization | 认证信息 |
| Host | 请求的主机域名(HTTP1.1中唯一一个必须包含的请求首部) |
| Connection | 是否需要持久连接。如果是close,表明客户端希望在本次连接后就断掉 TCP 连接 |
| User-Agent | 客户端的浏览器类型 |
| Referer | 包含一个URL,用户从该URL代表的页面出发访问当前请求的页面 |
| Content-Type | 实际发送的数据类型(表单提交、文件上传、json等) |
| Content-Length | 请求消息正文的长度 |
| Pragma | 指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝 |
一个简单的例子是,当我们访问 https://developer.android.com/studio/index.html 想要下载 Android Studio软件时,如果我们用的是Windows 系统的浏览器,页面则会默认显示Windows版本的Android Studio软件下载,反正如果我们用的是 Mac 系统,则会默认显示 Mac 版本。这就是因为服务器根据我们的 User-Agent判断我们是当前什么系统。
如果一个首部行有多个值,通常用 q=0.9 来排列相对优先级,如
accept-language: zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7如果是 POST 方法,在 首部行 后面会有一个空行,紧接着是 请求包体(request body),包括了表单中提交的内容。 Content-Type 指定了请求的数据类型。
示例:不同 Content-Type 的请求
application/x-www-form-urlencoded (表单提交)
POST /foo HTTP/1.1
Content-Length: 68137
Content-Type: application/x-www-form-urlencoded
account=123&name=jerrymultipart/form-data(表单提交或文件上传)
POST /foo HTTP/1.1
Content-Length: 68137
Content-Type: multipart/form-data; boundary=---------------------------974767299852498929531610575
---------------------------974767299852498929531610575
Content-Disposition: form-data; name="description"
some text
---------------------------974767299852498929531610575
Content-Disposition: form-data; name="myFile"; filename="foo.txt"
Content-Type: text/plain
(content of the uploaded file foo.txt)
---------------------------974767299852498929531610575application/json
POST http://www.example.com HTTP1.1
Content-Type: application/json;charset=utf-8
{"name":"jerry","sub":[1,2,3]}text/xml
xml文本
text/plain
纯文本
http response 报文
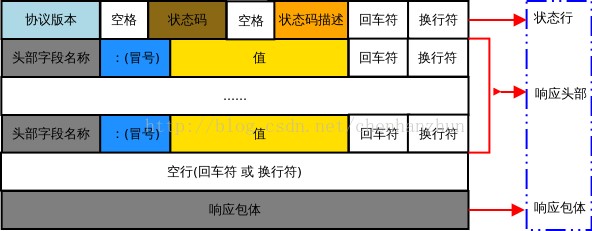
HTTP/1.1 200 OK
Connection:close
Content-Type:text/html; charset=UTF-8
Date:Thu, 08 Mar 2018 08:37:21 GMT
Expires:Thu, 08 Mar 2018 09:07:21 GMT
Pragma:no-cache
Server:Apache/2.2.15 (CentOS)
Transfer-Encoding:chunked
X-Powered-By:PHP/5.3.3
(data)状态行
第一行称为 状态行(status line),这一行包括了协议和状态码。常见的状态码有:
- 200 OK: 表示请求成功
- 301 Moved Permanently: 重定向转移
- 400 Bad request: 请求不能被服务器理解
- 404 Not Found: 请求的对象在服务器上找不到
- 500 Internal Server Error:服务器已收到请求,但服务器内部出错导致无法响应
首部行
第一行后面几行称为 首部行(header line),内容与 request 的首部行大同小异。
最后是数据,也就是被请求的对象。如果请求的是 html 页面则在浏览器显示网页,如果请求的是图片则显示图片等。
cookie
HTTP是无状态协议,那么网站是怎么识别我们的呢? cookie 用于站点对同一用户进行识别,在无状态的 HTTP 之上建立一个用户会话层。
cookie技术有 4 个组件:
- request报文首部中有一个 cookie 的首部行
- response报文首部中有一个 cookie 的首部行
- 客户端系统中有一个 cookie 文件,由浏览器进行管理
- 服务器后端数据库中有 cookie 相关数据
比如说,当我们第一次登录 JD.com 进行购物的时候,JD服务器的 response 报文会对我的浏览器设置一个 set-cookie: 1678 的首部行,这个 set-cookie 把 cookie 值存入了我们的电脑。然后我们点击几样商品,转入购物车结算页面,此时对 HTTP 来说是一次全新的连接,但是结算页面却能准确显示我们刚才选的商品,这是因为我们在进入结算页面时,request首部中包含了刚刚 JD.com 给我们的 cookie: 1678, JD.com 就知道你是刚刚 1678 那个人了,于是把刚才页面你勾选的商品显示出来,进行结算。
Cookie 和 Session 的区别和联系
在某些地方你可能会听说过 Session 这个名词,简单地说,Session是在服务端保存的一个数据结构,可以是任何类型的数据。它用来跟踪用户的状态,这个数据可以保存在内存、集群、数据库、文件中,但总而言之是保存在服务器端的,对客户端不可见。
而 Cookie 是客户端保存用户信息的一种机制,Cookie只能存储字符串,用来记录用户的一些信息,也是实现 Session 的一种方式。由于保存在客户端,因此最好对 cookie 进行加密。
例如,在 Java Servlet 开发中,我们可以这样设置 cookie:
// 设置 cookie
Cookie cookie = new Cookie("key","value");
cookie.setMaxAge(60*60*24); // 设置 cookie 有效期
response.addCookie(cookie);
// 读取 cookie
Cookie[] cs = request.getCookies();代理服务器
Web 缓存器(Web cache),或者叫 代理服务器(proxy server)。用于存放真实服务器上面的一些对象。提高用户访问速度。
比如说,我们访问 www.somesite.com/campus.gif , 如果对方服务器有配置代理服务器,则我们的请求会首先发给代理服务器,代理服务器检查自己有没有这个文件,如果有,直接 response 给客户,如果没有,代理服务器向真实服务器请求这个文件,获取到以后先自己复制一份,然后发送给客户。
这样做的好处就是降低了服务器的压力(因为服务器除了存储对象还有其他事要干,资源获取这种简单的活就交给代理服务器去干了)。同时,也有利于提高用户访问速度。
条件 GET 方法
使用代理服务器有一个问题,那就是代理服务器缓存的对象,也可能是旧的。比如今天缓存了一张图片,明天真实服务器修改了这张图片,后天有一个浏览器请求这张图片。如果代理服务器直接发给客户,不就发了旧版本吗?
解决方案是条件 GET 方法, 这个 GET 方法 由代理服务器向真实服务器发出,其中包括 If-Modified-Since 首部行(表示自XX时间点后对象是否有修改),值为上次请求真实服务器的时间,如果真实服务器返回 304 Not Modified(未修改),则证明对象是最新的,否则,返回最新的对象。
URL 和 URI 的区别
URI:Universal Resource Identifier 统一资源标志符 URL:Universal Resource Locator 统一资源定位符 URN: Universal Resource Name 统一资源名称
也就是说,URI分为三种,URL or URN or (URL and URN)
HTTP 中 URL 的参数
如果我们:
- 登录知乎 https://www.zhihu.com/
- 搜索“Spring”,回车。
会发现,浏览器的地址变成了
https://www.zhihu.com/search?type=content&q=Spring其中, ?type=content&q=Spring 部分就是参数。
参数由 ? 开头,每个参数形如 name=value 的形式,多个参数用 & 符号连接。
HTTP参数实际上可以认为是一种用户的输入,根据不同的用户输入,服务器经过处理后返回不同的输出。
http、tcp、socket
当浏览器需要从服务器获取网页数据的时候,就会发出一次Http请求。Http会通过TCP建立起一个到服务器的连接通道,当本次请求需要的数据完毕后,Http会立即将TCP连接断开,这个过程是很短的。所以Http连接是一种短连接,是一种无状态的连接。所谓的无状态,是指浏览器每次向服务器发起请求的时候,不是通过一个连接,而是每次都建立一个新的连接。但是从http/1.1之后,也支持 keep-alive 保持连接功能。
如果要说 http 和 socket 有什么区别,那就是 http 是一种规定好的连接模型,而 socket 我们可以自由编程控制什么时候保持连接,什么时候断开,但他们两者本质上传输的都是底层tcp连接所建立的数据。
比较形象的描述:HTTP是轿车,提供了封装或者显示数据的具体形式;Socket是发动机,提供了网络通信的能力。
安全的 http 协议: https
http 协议及承载它的 TCP/IP 协议,在设计之初没有考虑到安全问题,Request 和 Response 的报文全部都是明文传输的,然而互联网江湖险恶,一来一回之间,内容可能被第三方看到,导致信息泄露,内容被伪造篡改等问题。
Netscape公司发明了 SSL(安全套接层,Secure Socket Layer)协议,在 TCP/IP 和 http 中间加了一个安全加密层,后来互联网标准化组织 IETF 在 SSL 3.0 的基础上重新优化设计,使其不仅仅可以加密 http,还可以加密其他应用层协议(甚至是 IP ),命名为 TLS (安全传输层,Transport Layer Security),目前最近的版本是2018年发布的 TLS 1.3。
于是乎,目前我们将 用 TLS 安全保护的 http 通信,称为 https 。
那么, https 是怎么保护 http 的呢 ? 其实无非就是服务器在发送数据前先用对称加密算法把数据加密,客户端接收到数据后,用相同的方式解密。那么问题来了,加解密的密钥,服务器应该怎么给到客户端?实际上,密钥交换的过程采用的是非对称加密方式,服务器和客户端在建立连接时,分别先把公钥用明文给到对方,这样只有自己的私钥才可以解。但是这样仍然有一个问题,公钥明文传输仍然可以被劫持,如何证明浏览器收到的公钥一定是该网站的公钥,而不被第三方“狸猫换太子”呢?
为了解决这个问题,人们发明了“数字证书”,由CA机构(Certificate Authority)颁发,一个网站如果想上 https,首先需要向CA机构申请数字证书备案,之后服务器把证书传输给客户端,客户端从证书里获取公钥就行了。那么,证书会不会被篡改呢?实际上证书包含了一段签名,只有CA机构的私钥才可以解,因此证书是不会被篡改的。而证书里面包含了网站的域名等信息,因此也没法掉包。
简单地说,https 就是浏览器先获取目标服务器网站的数字证书,在证书里取到公钥,使用非对称加密交换对称加密的密钥,再用对称加密传输数据。
参考
- 参考书籍:《计算机网络:自顶向下方法》
- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎