
Crash Course AI(16-20)
P16 实践课:构建一个电影推荐系统
配套实验代码:Recommender Systems Lab: Crash Course AI #16
我们当然可以找到网上评分高的电影,跟朋友们一起看,但是你们喜欢的电影类型可能截然不同,他喜欢爱情片,你喜欢动作片,所以通用的推荐可能不太实用,我们需要的是,根据我们俩过去分别看过的电影,个性化地推荐出同时适合我们两个的电影。
步骤一:收集并清洗数据
为了推荐电影,我们需要先找到并导入一个电影数据集。MovieLens 是个不错的选择,它最小的数据集其中包含大约10万条用户评分,涵盖大约1万部不同的电影。这些数据集包括了不同的用户对不同的电影的打分情况。
有一些电影可能非常冷门,只有1个人打过分,因此第一步我们需要先对数据做一下清洗,过滤出超过20人打分的电影。
步骤二:尝试通用推荐
我们可以在数据集中查找,找出两个人都喜欢的电影类型(比如他喜欢爱情片,你喜欢动作片,就寻找既有爱情标签,也有动作标签的电影),遗憾的是,通用推荐可能出现我们已经看过的电影,所以不一定奏效。
步骤三:录入个性化数据
为了实现个性化推荐,我们需要录入我们各自已经看过的电影及对应的打分,以便推荐系统不再重复推荐,并找出同时合适我们两个人口味的电影。
步骤四:用户-用户协同过滤
协同过滤(Collaborative Filtering)有很多种,包括项目-项目(Item-Item)协同过滤、用户-用户(User-User)协同过滤、潜在因子分析(latent factor analysis)等等,但是用户-用户方法非常常见,非常适合作为入手。在用户-用户协同过滤中,每个项目都是一个独立的维度。因此,如果我们的数据集中有 10,000 部电影,那就是 10,000 个维度。处理数千个维度和大量缺失数据需要巧妙的线性代数和统计学知识,我们可以使用 LensKit 库来进行这些数学运算,并理解其工作原理,但从概念上讲,无需深入细节。
无监督学习:聚类
这里我们以2个电影作为例子进行可视化理解,假设我们有一个图表,其中一个轴是电影《盗梦空间》,另一个轴是《恋恋笔记本》。在这个例子中,我们将绘制所有看过并评价过这两部电影的人的评分,用户-用户算法会尝试将对电影评分相似的用户聚类,这是一种经典的无监督学习方法。
这些聚类没有“正确”的大小,所以我们必须设置两个参数:
- 最小邻域大小(minimum neighborhood size):应该放入一个聚类中的最小人数,如果太大,那么会将相对不太接近的人被迫聚类到一起。
- 最大领域大小(maximum neighborhood size):应该放入一个聚类中的最大人数,如果太大,可能会导致推荐过于笼统。
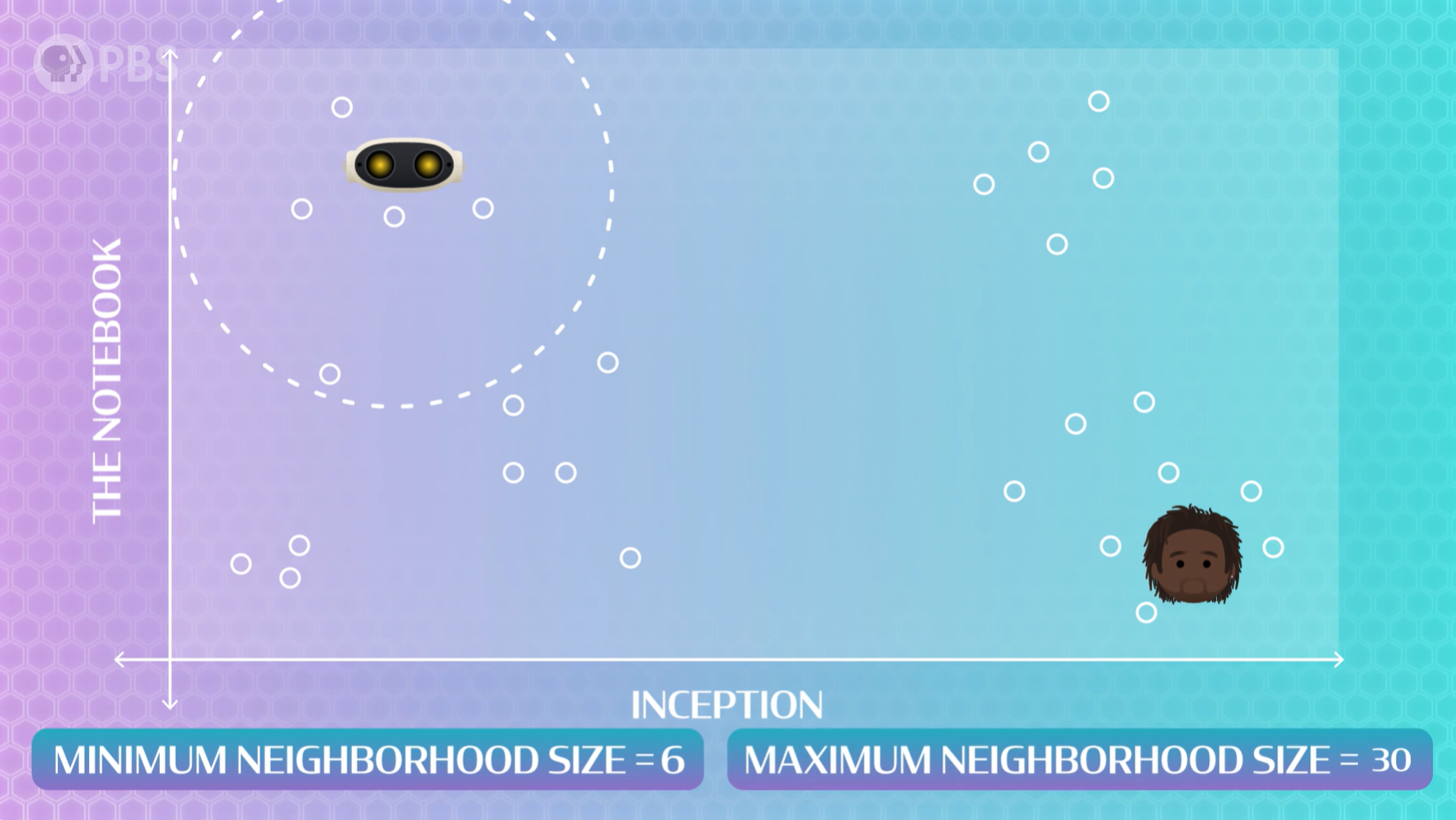
找到最佳聚类方法需要大量的尝试,没有一个最佳值。较小的邻域规模意味着AI会考虑更少但电影口味更相似的用户,用于预测的数据会更少,但得到冷门但出乎意料适合你的电影概率高。较大的邻域规模意味着AI会考虑更多但电影口味差异较大的用户,用于预测的数据会更多,得到一些普遍流行且广为人知的电影概率高。如果你真的找到了最佳方法,恭喜你,发明了Youtube,你可以开始向数十亿不同的在线用户推荐视频了。
监督学习:预测
在确定好人群聚类后,算法利用聚类中用户的历史数据,开始使用监督学习方法进行训练,找出在聚类中相似的人看过的其他电影。然后找出你可能喜欢的十部电影,再找出你朋友喜欢的十部电影。如果这里面有重叠,那就在重叠的清单里挑选一部。
如果你们压根不是同类人,聚类差得相当远,根本没重叠怎么办呢?可以把你们都看过的电影找出来,取你们打分的平均值,把这个平均后的打分数据作为一个“混合人”,然后为这个“混合人”进行协同过滤推荐。
如果你们压根没看过相同的电影怎么办?这时候,最有效的办法就是最简单的办法,你们一起看要么你看过,要么他看过的电影,再看一遍又何妨呢。
P17 Web搜索
搜索引擎
搜索引擎(Search engines)是现代生活中不可或缺的一部分。它帮助我们获取信息、查找路线、购物,以及参与关于热狗是不是三明治的争论。
本质上,搜索引擎收集数据,创建组织系统对数据进行排序,并找到与问题相关的结果。与大多数人工智能系统一样,第一步需要收集大量数据。搜索引擎收通过 网络爬虫(Web crawler) 程序来实现数据收集,爬虫先从某个种子网页开始,下载该网页并找到它的所有引用链接,然后,访问这些引用链接,继续找出它们所有的引用链接,依此类推……直到爬取整个 Web。
收集完所有数据后,下一步是构建索引来组织数据,用于组织网页的索引称为 倒排索引(inverted index)。例如我们在搜索引擎中输入“成吉思汗是谁?”,搜索引擎利用这个倒排索引来查找“谁”、“是”、“成吉思汗”和“汗”这些词,可能会发现某些网页至少包含问题中的一个词,之后再对这些网页按相关性进行排序。实际上,我们每次在谷歌上搜索和点击,都在给谷歌的人工智能提供训练数据,例如,我们点进一个网页,发现跟我们想搜的关系不大,于是关闭退出,再点进下一个网页,谷歌通过判断你在每个网页的跳出率和点击率,判断搜索词和网页的相关性,以决定它们的排序。
问答助手
有时候我们想问,“明天的天气怎么样?”,我们希望直接得到答案,而不是浏览搜索结果。一些问答助手如 Siri 是通过知识库来向我们回答的,原理有点像前几节提到的符号人工智能,知识库的主要问题之一是很难记录宇宙中的所有事实,但计算机需要被告知某些常识,然后AI通过逻辑推理得出更多事实。
就像我们在写论文时寻找多个来源一样,AI会重复使用并结合多个来源来增强对它找到的事实真实性的信心,并且会一遍又一遍地使用已知的关系来寻找新的对象,再用已知的对象来寻找新的关系——从而创建一个庞大的知识库。
当我们问出一个问题,如果AI之前提取过该信息,它就可以在知识库中找到匹配项,并返回最可靠的结果。其底层跟 词性标注系统(speech tagging systems) 的研究有关。
备注:此课程上线于2019年,彼时大语言模型还未流行,问答助手多基于符号AI实现,站在2025年的今天回过头来看,问答助手已经逐渐从符号主义转为联结主义,使用大语言模型来实现,例如 chatGPT、Deepseek、Gemini 等。大语言模型是把整个人类的知识作为参数全丢进神经网络,并通过注意力机制进行训练的神经网络模型。
P18 算法偏见与公平性
算法本质上就是数学和代码,但算法是由人创建的,并且使用我们的数据,因此现实世界中存在的偏见会被AI系统模仿甚至放大,这种现象被称为算法偏见。偏见本身不是坏事,重要的是,要了解偏见(我们每个人都有)和歧视(我们可以预防)之间的区别,这将帮助我们避免未来AI被用于有害的、歧视性用途。
隐藏的偏见
AI训练数据可以反映社会中隐藏的偏见。例如,“护士”一词更有可能指代“女性”,而“程序员”一词更有可能指代“男性”。
无意的相关特征
有人认为只要我们不收集或使用对种族或性别等受保护类别进行分类的训练数据,那么我们的算法就不会出现歧视。然而,受保护类别可能会以相关特征的形式出现,这些特征并非明确地存在于数据中,但可能无意中与特定预测相关。例如,邮政编码可能与种族密切相关,购买记录可能与性别密切相关。
有些特征难以量化
训练数据中的某些特征很难量化,因为很多东西很难用数字描述。例如,AI阅卷,好的作文包含清晰性、结构和创造力等复杂要素,但AI难以评估文章中情感的部分,以至于胡编乱造但辞藻华丽的文章被AI判高分。
正反馈循环
算法可能形成正反馈循环。例如,AI分析某个地方犯罪率高,于是那里被派去更多警察,查处的犯罪记录多了,这些记录又成为算法的训练数据,导致AI预测那个地方的犯罪率会更高。而其他地方虽然也有犯罪,但因为没被那么多警察,所以没被发现。
训练数据可能被篡改
2016年微软在美国发布了推特机器人Tay,在发布12小时后,由于“部分人员的协同攻击”,Tay的数据集遭到篡改,Tay开始发布暴力、性别歧视、反犹太主义和种族主义的推文。人工智能可以被操纵这一事实意味着我们应该对算法预测持保留态度。
P19 实践课:养猫还是养狗
配套实验代码:Recommender Systems Lab: Crash Course AI #19
如果我们想领养一只宠物,但不知道养猫还是养狗会让我们更快乐,或许,我们可以构建一个AI系统帮助我们决策。
步骤一:收集数据
首先,我们要收集关于人们的猫和狗以及它们幸福感的数据。我们不在乎养什么宠物,只要它能带来快乐就行,所以我们不会在模型中包含猫和狗的标签。对于宠物来说,或许可以用这四个特征:爱撒娇、柔软、安静、以及精力充沛。
于是我们开始制作一份调查问卷,里面包含关于这四个特征的问题,并到公园去随机询问人们他们的宠物是否符合这些特征,以及是否能让他们感到快乐。在收集的所有答案中,我们绘制成一个表格,包含这四个特征和幸福感总共五列数据,1表示是,0表示否。
# Column names: Energetic, Cuddly, Soft, Quiet, Happiness
survey = np.array([
[1, 0, 1, 1, 1], # Energetic, Not Cuddly, Soft, Quiet, Happy
[1, 1, 1, 1, 1], # Energetic, Cuddly, Soft, Quiet, Happy
[1, 0, 1, 0, 1], # Energetic, Not Cuddly, Soft, Loud, Happy
[0, 0, 1, 0, 0], # Not Energetic, Not Cuddly, Soft, Loud, Not happy
[0, 1, 0, 1, 0], # ...
[0, 0, 0, 1, 0],
...
...
[0, 1, 1, 1, 1]
])记得把数据集分为训练集和测试集。训练集用于训练神经网络,测试集在训练过程中对神经网络隐藏,这样之后就可以用它来检验神经网络的准确率。
步骤二:构建和训练神经网络
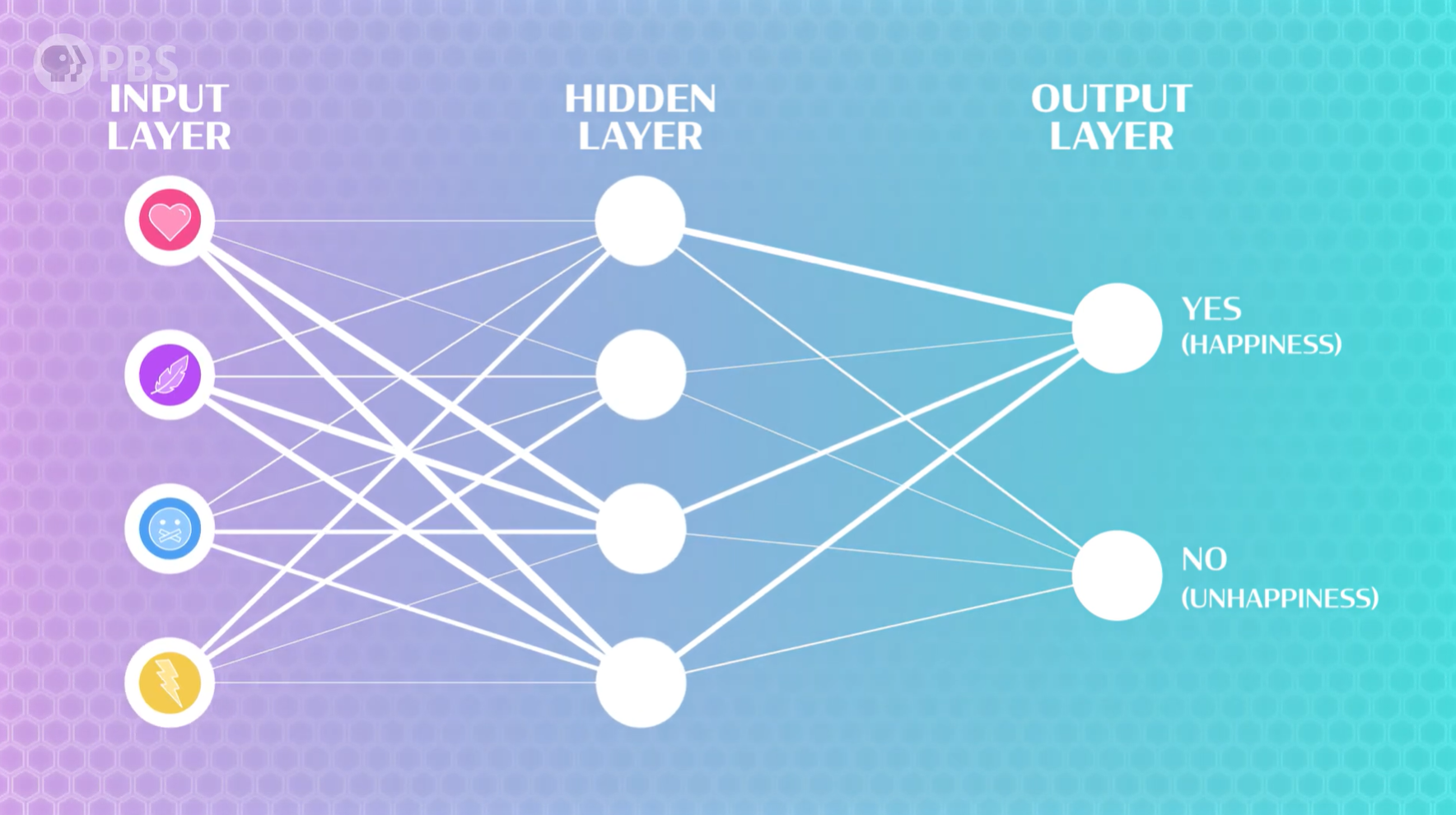
我们依然使用 多层感知器神经网络(MLP),这个神经网络有一个用于接收上述4个特征的输入层,以及若干个隐藏层(用于寻找特征之间的关系,帮助模型做出准确的预测),最后还有一个输出层(输出是否带来快乐)。
Python 中的 SKLearn 的库已经包含了MLP算法,可以直接使用,SKLearn 会自动计算输入和输出的大小,所以我们只需要指定隐藏层的大小,以及迭代次数。
当模型循环处理数据时,它会根据特征预测快乐程度,将其预测结果与实际调查结果进行比较,并更新其权重和偏差。经过多个周期的训练,同一训练数据集的预测结果应该会不断提高!
步骤三:验证
我们可以用最初的训练数据测试AI,看看它捕捉到的信息有多准确,当然,我们也预留了测试集。这里的输出结果让我们知道我们的神经网络在预测这些宠物特征是否能预测主人幸福感方面表现如何。
步骤四:反猫偏见的分析
当我们进行真实的选择时,会发现AI对于狗预测的大部分是 yes,而对于猫预测的都是 no,很明显,AI出现了“反猫偏见”。这时候我们应该回去分析数据和模型,看看是哪里出了问题。
排查数据问题
我们首先排查数据问题,先看看数据中狗主人感到幸福的比例和猫主人感到幸福的比例,我们发现差不多,这说明猫确实能带来幸福,所以应该不是这个问题。再看看是不是数据中狗主人和猫主人的人数差距太大,如果是,导致数据差异的原因可能是调查地点出了问题,比如说,公园里养狗的人会更多,而街边店铺养猫的会更多。
排查特征选择问题
重新调查修正了数据问题后,我们发现AI预测依然对猫有偏见,于是我们猜测是不是特征选择的原因。我们发现,几乎没有一只猫是精力充沛的,因此,这是一个相关特征,即一个(无意中)与特定预测或隐藏类别相关的特征,也就是说,在这种情况下,知道某个东西是否精力充沛就相当于知道它是狗,模型可能因此认为如果宠物精力充沛,主人就会感到快乐。从数据上看也是如此(如果宠物精力充沛,主人很可能对它感到满意,无论其他特征如何)。所以,将精力充沛作为特征,似乎不太合适,因此我们去掉这个特征。
避免偏见
有时候,某些特征可能是唯一可衡量的值,因此我们不能简单地删除。这时候需要有人检查结果并提出一些重要问题以避免偏差,例如:
- 数据是否符合我的目标?
- 人工智能是否拥有正确的特征?
- 我真的在优化正确的事情吗?
总之,在构建人工智能系统时,并非总有简单万无一失的解决方案。你必须不断迭代你的设计,并尽可能地考虑各种偏差。
P20 人工智能的未来
人工智能是新的电力 —— 吴恩达
通用人工智能(AGI)
今天的人工智能能力仍然有限,但这不妨碍我们试图去想象一种适用于所有应用场景的终极人工智能:通用人工智能(Artificial General Intelligence,AGI)。
为什么我们要追求 AGI ?1950年,艾伦·图灵提出了著名的“图灵测试”,目的是测试机器对任何人类事物的智能,无论是数学还是诗歌。我们不会去评判机器人的人造皮肤看起来有多“逼真”,正如图灵所说:“我们不希望因为机器在选美比赛中表现不佳而惩罚它,也不希望因为人类在与飞机的比赛中输了而惩罚他”。这个想法暗示了人工智能的一个统一目标:通用人工智能(AGI)。
尽管我们不确定 AGI 是否可能,但许多社区正在进行跨学科研究,许多研究人员正在迈出小小的步伐将各个专业子领域结合起来。例如教机器人理解语言,或者教一个模拟股市的AI系统阅读新闻并理解市场波动。
AI发展正在加速,越来越平民化、个性化
如今,越来越多的人(包括我们,包括AI自己)正在学习如何构建人工智能系统,所有的问题都拥有大量数据,可用于训练新的算法,所以人工智能的发展也会越来越快。全球各地的创客社区正在结合数据、算法和消费级硬件来创造未来并实现人工智能技术的个性化。
AI未来的思考
人工智能可能导致失业,但也创造了新的岗位;人工智能能够帮助产出,但也消耗了能源;人工智能能够帮助决策,但也有潜在的偏见;人工智能带来了生活的便利,但也可能因过度收集数据导致隐私泄露……总而言之,我们必须权衡大规模部署人工智能的收益和成本。
关于人工智能的未来,仍有很多值得思考的地方。但主动去了解人工智能,这样当我们看到一家公司或政府推出一项新技术时,我们就知道应该问哪些问题:
- 他们的数据来自哪里?
- 我们真的希望人工智能帮助人类吗?
- 这是合适的工具吗?
- 为了这个炫酷的新功能,我们放弃了哪些隐私?
- 有人在审核这个模型吗?
- 这个人工智能真的实现了开发者的预期目标吗?
