
Crash Course AI(11-15)
P11 机器人(Robotics)
机器人技术涉及很多领域(计算机科学、机械工程、人工智能等)。在人工智能领域,机器人技术充满了巨大的挑战,我们重点关注机器人学中的三个核心问题:定位、规划和操作。
定位(Localization)
机器人最基本的功能是与世界互动。为此,它需要知道自己在哪里(定位)以及如何到达其他地方(规划)。定位和规划密不可分,我们人类就一直在进行定位和规划。
当我们走在路上,想进去商场时,我们环顾四周,构建我们的心理地图,观察路面、墙壁、扶梯、和门,然后找到商场入口并进去。一旦有了心理地图,并且知道了去商场的路,下次我们就能更快到达那里。这些输入都是通过我们的眼睛感知到的,而且我们人类天生有立体视觉。机器人如果要在世界上移动,也需要构建心理地图,当它们探索时,需要同时跟踪自身位置并更新它们所看到的心理地图,这个过程称为 同步定位与地图构建(Simultaneous Localization And Mapping),简称 SLAM 。
机器人的眼睛就是各种摄像头,有些机器人为了实现立体视觉,至少需要两个摄像头。许多机器人使用RGB摄像头采集世界的彩色图像。有一些还配备传感器,例如红外深度摄像头,通过发射人眼不可见的红外光来测量距离(测量红外光反射回来的时间),一些视频游戏的运动传感器就是这样来确定玩家的位置和手势的。
许多自动驾驶汽车使用一种名为 激光雷达(LiDAR) 的技术,每秒发射超过10万次激光脉冲,并测量这些脉冲的反射回来的时间,这可以生成一张世界地图,标出平面以及三维物体的大致位置。一旦机器人知道物体的远近,它们就可以构建自己认为的世界地图,并更安全地绕过障碍物。通过每次观察并记录自身的路径,机器人就可以更新其心理地图。
规划(Planning)
规划是指人工智能将一系列事件串联起来以实现某个目标,而这正是机器人技术可以与符号人工智能(Symbolic AI)联系起来的地方。
当扫地机器人已经被训练学习了家里的地图,我们可以指挥它去打扫厨房。这时候,它就开始制定行动计划,为了制定计划,我们需要先定义动作,而动作需要前提条件(物体在世界中的当前状态)。比如说,当在当前位置和厨房之间有一扇门时,他可能想要使用“开门”动作穿过这扇门,这个动作的前提条件是门是关闭的,其效果是门会打开。
机器人还需要考虑不同的可能行动序列(包括它们的前提条件和效果),以便推理通往厨房的所有路线,并选择一条路线。
操控(Manipulation)
我们人很擅长掌握一些操作,例如拿扫帚扫地。本体感觉(proprioception) 和 闭环控制(closed loop control) 是帮助我们进行操控的两个特性,对机器人也是一样。
本体感觉是指我们即使看不见四肢,也能知道身体的位置和运动状态。我们的神经系统和肌肉帮助我们的身体感知本体感觉。但大多数机器人需要传感器来判断它们的机械部件是否在运动,以及运动速度如何。
闭环控制,就是带反馈的控制。我们用眼睛感知,用肌肉控制手臂和手指,它们之间形成了一个闭环——它们都是我们身体的一部分,并与我们的大脑相连。如果东西很重,我们的手会有重感,大脑会收到感知,然后让手抓紧一点,这就是一个闭环。对于机器人,我们所说的“闭环”包括感知周围环境的传感器,以及控制周围环境的机械部件。在制造机器人时,闭环操控这个过程必须通过编程来实现,操作方式会因机器人的硬件和程序而异。但只要投入足够的精力,我们就可以让机器人执行特定的任务,比如从奥利奥饼干中取出奶油。
除了制造能够独立工作的机器人之外,我们还必须考虑机器人如何与其他机器人甚至人类进行交互和协调。事实上,有一个专门研究如何让机器人与人类合作或向人类学习的领域,叫做人机交互(Human-Robot Interaction)。这意味着它们必须理解我们的肢体语言以及口语指令。
机器人技术最令人兴奋的地方在于,它将人工智能的各个领域融合到一台机器中。未来,它或许能赋予我们超能力,帮助残障人士,甚至通过送零食让世界变得更便捷。
P12 游戏中的AI
研究人员花费大量时间尝试教AI在游戏中击败人类,除了游戏很有趣之外,也因为游戏通常有一个分数或一些客观的“获胜”衡量标准,这为测试新的AI算法和方法提供了合适的场景。AI甚至可以与自己对战来生成训练数据,并进化出更好的游戏策略。AI在很多策略游戏上已经被攻克,例如,2017年在围棋中战胜人类,2018年在DOTA2中战胜人类, 2019年在星际争霸2中战胜人类。
极小极大算法
让AI下棋,本质上是把棋盘当作一棵状态树,每种选择结果都可以被赋予一个奖励(例如,获胜为1,失败或平局为-1)。AI需要搜索遍历所有可能的结果树来找到获胜的路径,它要么选择最大化自己回合获胜结果的分支,要么选择最小化对手回合获胜结果的分支,这称为 极小极大算法(minimax algorithm)。该算法会根据每一步棋的概率赋予一个值,AI再根据自己的策略决定下一步怎么走。
蒙特卡洛树搜索
从头到尾画出完整的井字棋树,需要大约25万个棋盘,这看起来很多,但现代计算机只需半秒钟就能计算出这么多的选项。通过列出所有可能性并选择通往胜利的路径,AI就能解决井字棋问题。然而,对于一些复杂的游戏,例如围棋的棋盘状态有 10^250 个,这比宇宙所有原子数加起来还多,传统计算机不可能计算出如此多的棋盘状态。许多现代AI系统,包括谷歌的AlphaGo,使用了一种名为 蒙特卡洛树搜索(MonteCarlo Tree Search) 的算法,该算法使用随机性和概率来解决问题。
现代游戏AI结合了蒙特卡洛的随机性和常规的树搜索(如极小极大算法),通过猜测概率来决定搜索庞大树的哪一部分。简而言之,它们希望所搜索的那部分游戏树能够带来更高胜率。毕竟,估算少量选择比穷举计算博弈树的所有分支要快得多,有些计算机甚至可以实时进行这种估算。
进化神经网络
有一些游戏AI使用了 进化神经网络(Evolutionary neural networks),它使用环境作为输入(类似于强化学习),但这种方法引入了多个智能体,它们尝试多种神经网络结构,然后基于成功的结构构建下一代。比如 MarI/O ,我们通过告诉它哪些按钮可以按,以及在关卡中向“右”走得越远越好,让它学习如何玩《超级马里奥世界》。AI一开始会随机乱按按钮,但随着一些按键操作让它向右走得更远,它会记住并从这些成功的尝试中学习。
P13 实践课:训练 AI 玩游戏
我们将玩一个《垃圾爆破者》游戏,玩家的目标是扮演一个机器人在海洋中游泳,并摧毁垃圾,注意不能碰到垃圾,否则就会输掉游戏。之后,我们将训练我们的AI,让AI学会玩这个游戏(游戏的制作过程请参考配套代码,这里着重讲解训练AI的部分)。
课程配套代码:Games Lab: Crash Course AI #13

为了让AI学会玩这个游戏,我们考虑使用神经网络。
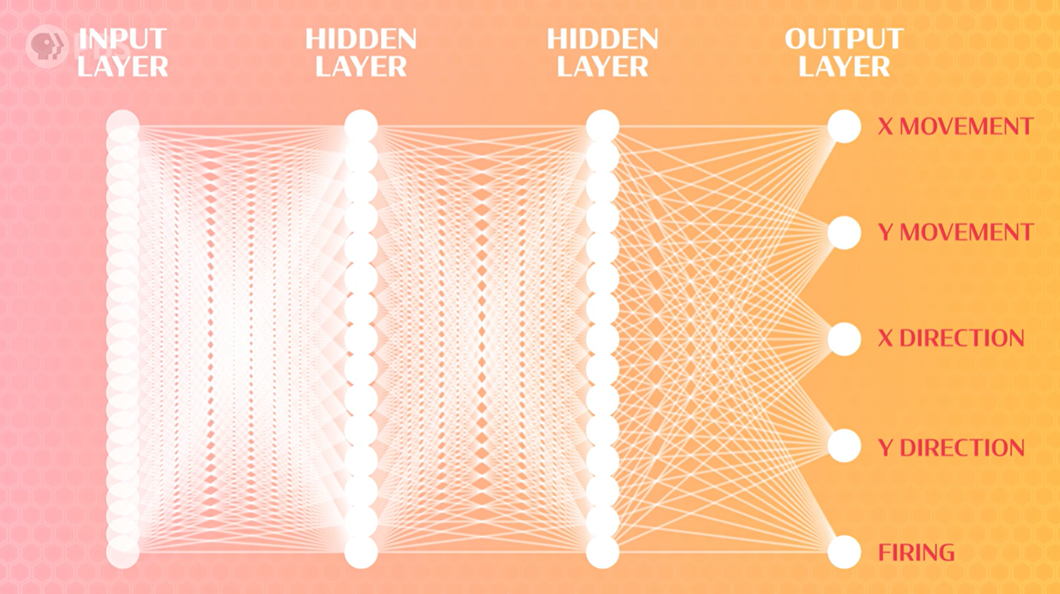
对于输入层,我们考虑距离玩家最近的5个垃圾(包括垃圾的大小、位置和移动方向),所以我们需要找到垃圾相对于角色的X轴和Y轴位置、相对于角色的X轴和Y轴速度,以及垃圾的大小。每个垃圾需要5个输入,那么5个垃圾需要25个输入。
对于隐藏层,我们先随便设置,例如创建2层,每层15个节点,之后可以调整。
对于输出层,总共会有5个节点:一个用于移动的 X 和 Y 坐标节点,一个用于瞄准的 X 和 Y 方向节点,以及一个用于决定是否发射光束的节点。
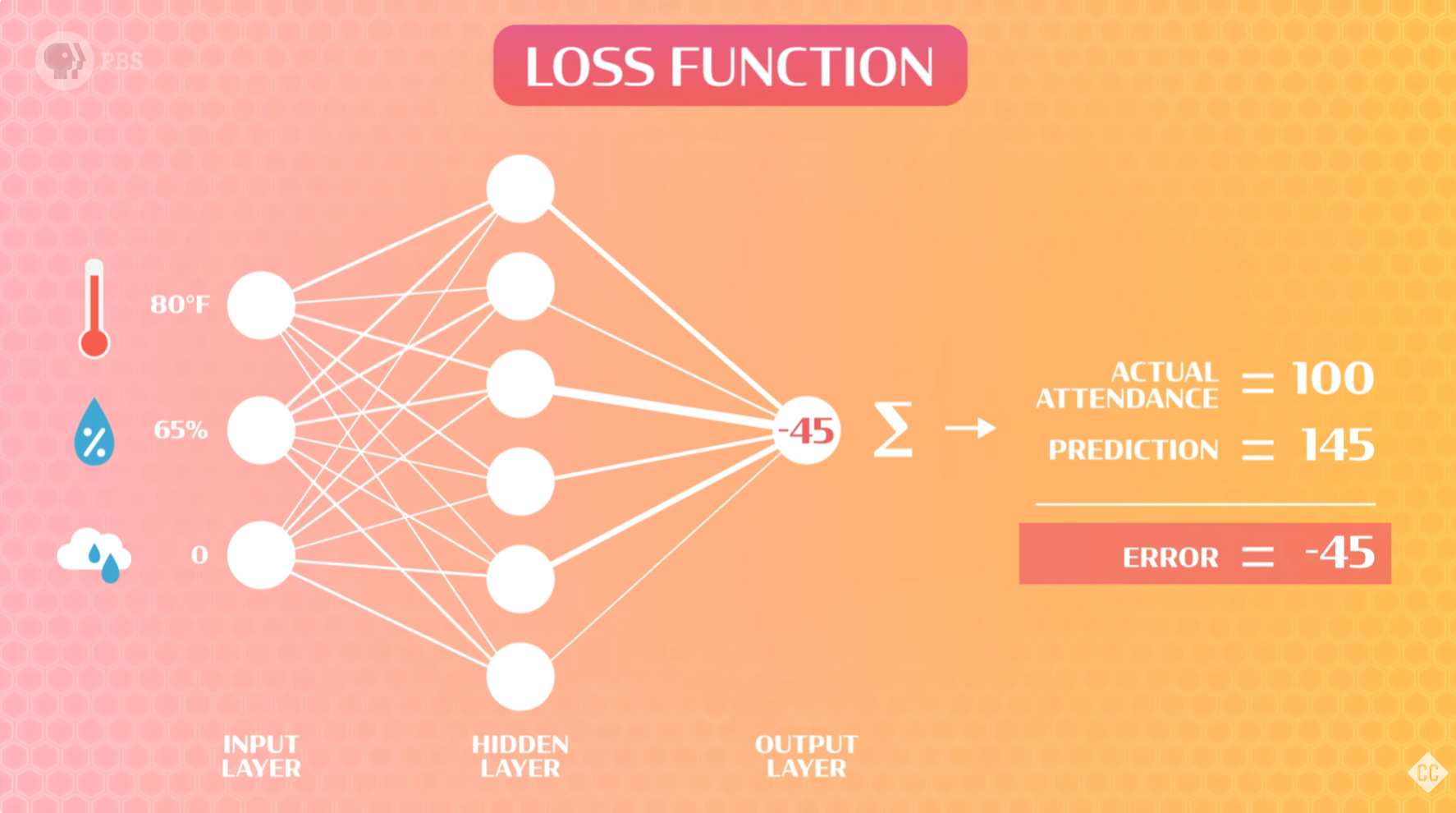
神经网络的初始权重为 0,因此 AI 第一次游戏时,它基本上什么也不做。我们使用强化学习策略,基于AI从游戏开始到结束的所有动作来训练它,并进化出一个更优秀的AI,其相关实现用到的是 遗传算法(GA,Genetic Algorithm) 。
首先我们会创建200个“空脑”AI机器人来玩游戏,其中一些运气好的家伙可能会存活下来,然后再选取得分最高的100个,并将它们全部克隆,作为我们的繁殖步骤。然后,我们将对这100个克隆的神经网络进行轻微且随机的权重调整,作为我们的变异步骤,变异会影响AI整体变化的程度,跟学习率的概念差不多。然后,我们反复评估、克隆和变异它们。随着时间的推移,遗传算法通常会生成在被要求执行的任何任务上逐渐表现更佳的AI。
当然,我们需要定义好什么是“表现更好”,是指摧毁大量垃圾?是指长时间存活?是指发射子弹的命中率?编写这个函数几乎是最重要的部分,因为我们如何定义适应度将影响AI的进化方向。如果没有平衡好,AI要么只发射子弹而不移动,要么成为“躲避大师”而不发射子弹,要么成为英雄萨姆疯狂爆射。
# 平衡“表现更好”的函数
def calc_fitness(self):
# 每存活一秒,奖励+1 , 击中垃圾,奖励+10, 发射一次,奖励-2
return self.playTime*1 + self.hits*10 + self.blasts*-2之后,我们不断让AI玩游戏,让AI模型不断迭代,遗传算法需要时间来进化出一个好的模型。总而言之,AI玩得好不好,取决于遗传算法、精心设计的适应度函数,以及运气。
P14 人机协作
人工智能和人类拥有互补的技能。AI擅长搜索大量可能性,并做出一些明智的猜测,从而选择最佳方案,而且,它不会因为疲倦或饥饿而犯错。而人类拥有更好的洞察力、创造力和感知力,也更擅长解读社交信号。两者结合,人机协作,我们都有美好的明天。
人机协作的好处
- AI让我们专注于我们更擅长的事:AI帮我们负责那些需要记忆、机械反应和遵循规则的部分,这样我们就可以去专注于社会理解和直觉的部分。例如,当医生试图做出诊断时,他们会尝试运用自己的医学经验和直觉来理解患者的症状,AI通过筛选临床数据帮助分析,并突出最可能的诊断,这样医生就可以将他们的经验和直觉集中在最能发挥作用的领域。
- AI帮助我们构思新的发明或设计:例如,在工程设计领域,AI帮我们负责预定的物理约束(比如物体应该有多重或者它应该能够承受多大的力),这样我们就能够把时间花在思考最实用的设计和激发新的创意上。
- AI解放人的重复性劳动:AI可以使人们摆脱重复性的脑力劳动,从而让我们有更多的时间和精力去做与人互动的事情。
- AI执行特定任务:AI机器人可以赋予人们更强的力量、耐力去执行某些类型的工作,例如,远程操控的搜救机器人。
AI与道德
人机交互领域致力于研究和构建新的人工智能、机器学习和机器人系统,以补充和增强人类的能力。但是AI无法理解如果犯了错误可能会造成什么后果,或者其决策可能产生什么道德影响,所以我们会希望对AI在现实世界中的行为进行调节和过滤,以便我们能够确保它们符合社会价值观、道德规范。
此外,我们每天在网络上发帖、点赞、收藏、留言,也恰恰是在给AI提供训练数据,这带来一些隐私性问题,也是值得我们去思考的。
P15 推荐系统
推荐系统是一种人工智能,它试图理解我们的大脑,并向我们提供有用的建议。例如,淘宝会推荐我们可能感兴趣的商品,抖音会推荐我们可能感兴趣的视频。各种互联网平台都在尝试用不同的方法推荐产品和服务,底层本质上都是结合了监督学习和非监督学习技术。
然而,向我们推荐东西是一个难题,可能会产生许多意想不到的结果。例如,太依赖推荐,我们将只看到与我们想法相同的人发表的内容,可能会让我们陷入信息茧房。
三种常见的推荐方法
三种常见的推荐方法分别是:基于内容的推荐、社交推荐和个性化推荐。
- 基于内容的推荐:关注视频的内容,例如,我们的算法可能会推荐最新的视频,或者推荐来自优质创作者列表的视频(如何定义优质创作者?)
- 社交推荐:关注受众,例如推荐点赞数量多、观看人数多的视频(并非所有人都喜欢相同的内容,哪怕它足够优质)
- 个性化推荐:根据不同的人有不同的偏好(这些偏好是从你的点赞、评论、浏览等行为数据得出),从而推荐不同的内容(很难发现新的有趣的内容)
协同过滤
为了兼顾各种推荐方法的优势,推荐系统通常使用协同过滤(collaborative filtering),它结合了上面三种方法。它使用一个表格来标注我们看过的内容,关注的标1,看过但未关注的标0,没看过的留空。然后,它使用无监督学习(聚类)找到一些跟你的浏览情况相似的人,看看那些人是否关注某些你没看过的内容,然后用监督学习的方式预测你是否会关注,如果预测的结果是“是”,那么系统就会向你推荐这个内容。
简而言之,推荐的基本策略就是利用已知的用户信息来预测用户偏好。

推荐系统可能的问题
- 数据稀疏:平台收集的数据集通常非常稀疏,因为大多数人不会观看大多数视频(根本没时间!),而且,有些人习惯只看不赞。对稀疏数据集进行任何类型的分析都需要大量的计算,这会导致成本高昂,因此一些公司愿意牺牲一些准确性来降低成本。
- 冷启动:当我们第一次访问某个网站时,AI对我们了解不足,无法提供良好的个性化推荐。
- 没用的推荐:我们已经看过的视频,或者已经买过的商品,平台依然在给我们推荐。
- 刻板印象:推荐系统无法理解重要的社会背景,因此“统计上可能”的推荐可能会令人担忧,因为这可能会以一种令人不适的方式对用户进行刻板印象。例如,你是一名老师,系统就一直向你推荐教学相关的视频,拜托,上个班都烦了,下班刷个视频还推工作内容。
- 信息茧房:在社交媒体上,推荐系统可能会让我们陷入意识形态回音室中,在那里,我们往往只能看到与我们观点一致的人的意见,这会扭曲我们对世界的认知。我们每个人看到的互联网都略有不同
- 隐私担忧:为了所谓的“推荐”,我们的数据不断被收集,这确实也令人担忧。
在设计一个推荐系统时,最好明确地思考其中涉及的权衡取舍。