
Crash Course AI(6-10)
P6 无监督学习(Unsupervised Learning)
监督学习和无监督学习的关键区别在于我们试图预测什么。在监督学习中,我们试图构建一个模型来预测教师提供的答案或标签,在无监督学习中,训练标签基本上是由我们周围的世界提供的,而不是由老师提供的。无监督学习就是通过猜测来对世界进行建模,例如婴儿通过观察和模仿他人进行大量的无监督学习。
对世界进行建模的最基本方法是假设世界是由具有共同属性的不同对象组组成的。例如,我们可以用颜色来对花进行分类(黄色的花、紫色的花),也可以用花瓣形状(圆形花瓣、直立花瓣),或者是通过花卉(郁金香、向日葵)。快速识别不同的属性并创建分类称为 无监督聚类(unsupervised clustering)。
鸢尾花分类:K-means 聚类
我们对世界建模有一个关键假设:某些物体彼此之间比其他物体更相似。那么该如何做聚类分析呢?这里我们思考两个问题。
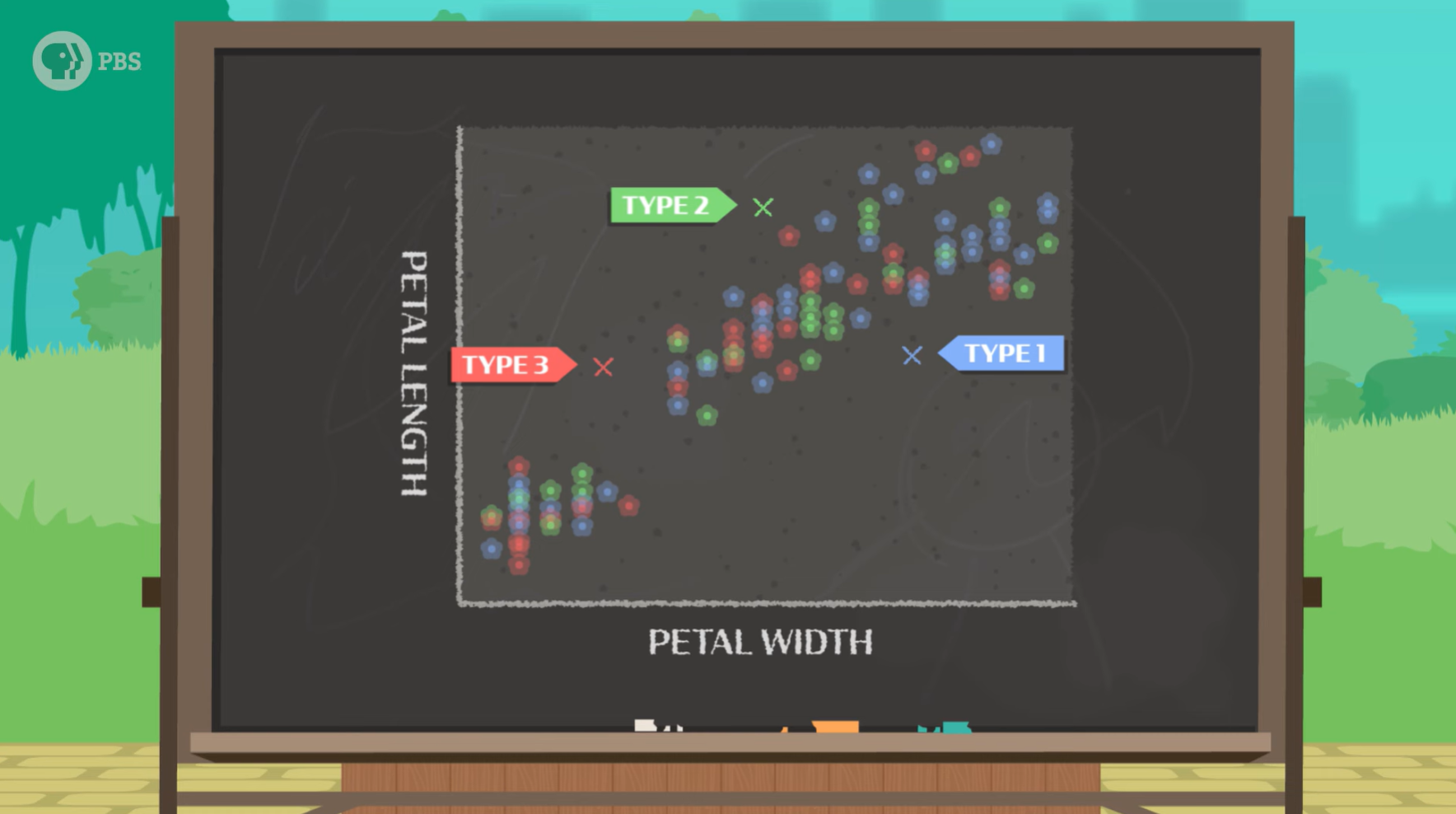
第一,我们如何测量?显然我们应该测量那些不同的观测值,不同的鸢尾花似乎有不同的花瓣长度和宽度,我们可以画一个图表,花瓣长度在 Y 轴上,宽度在 X 轴上。
第二,我们如何表示?这里我们假设数据中存在聚类,就是说,存在一些称为 K 个簇的群体,但我们不知道它们在哪里,于是,我们借助一种称为 K-means 的聚类算法来帮我们分类。
K-means 是一种简单的算法。它只需要一种比较观测结果的方法,一种猜测数据中存在多少个聚类的方法,以及一种计算它预测的每个聚类的平均值的方法。具体来说,我们希望通过将一个聚类中的所有数据点相加,然后除以点的总数来计算平均值。
无监督学习是关于对世界进行建模的,所以算法应该包含两个步骤,第一,预测,预测世界会是什么样子?(哪些花应该放在一起,因为它们是同一物种)第二,纠正(或学习),模型会更新其信念,使其与对世界的观察相一致。
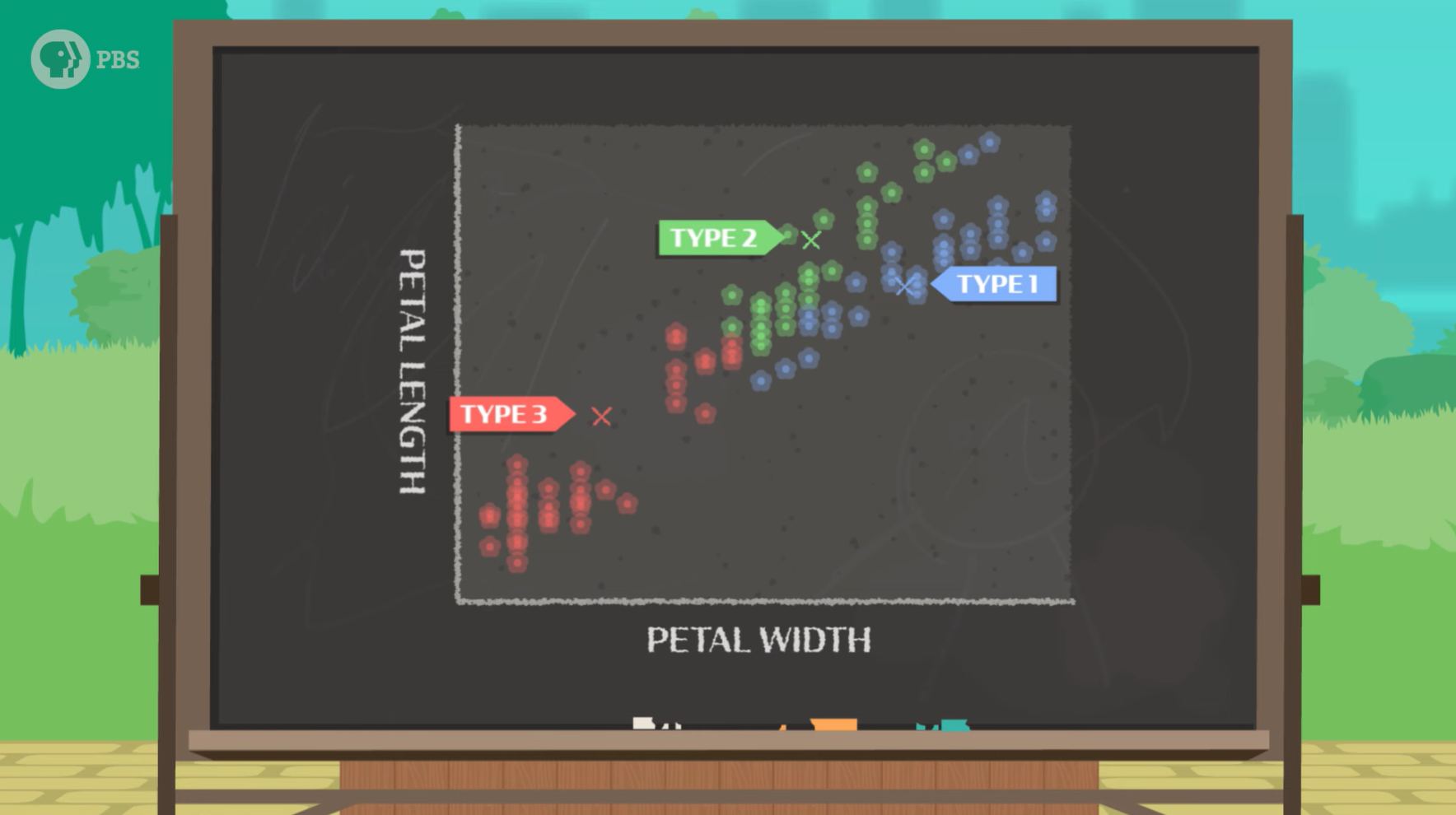
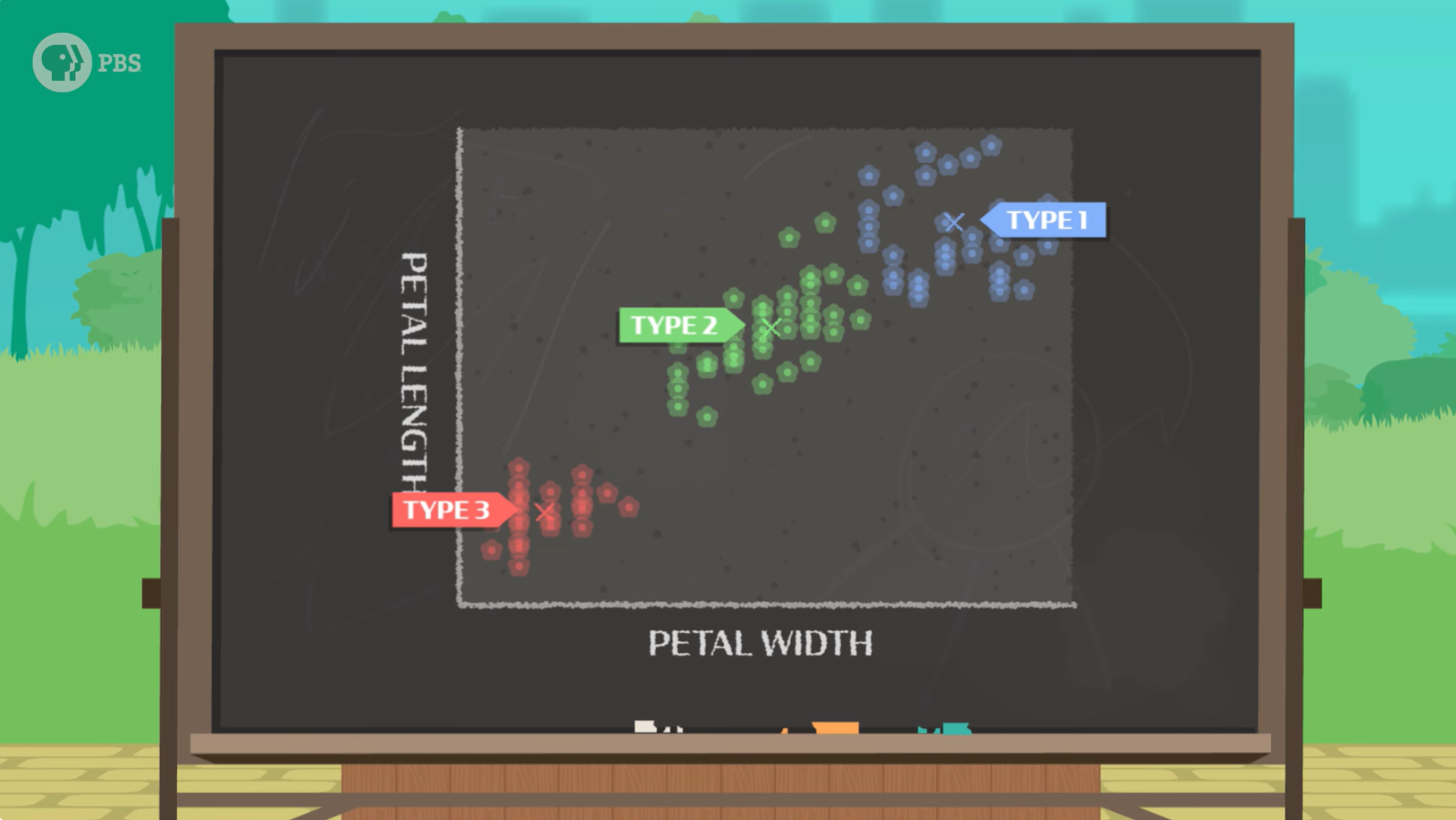
一开始,我们需要先指定模型应该寻找多少个聚类,这将成为模型对世界的初始理解,例如,我们正在寻找 K=3 的平均值(三种类型的鸢尾花)。于是图表中每一个数据点(意味着一朵花)都会被随机标记为是类型1,类型2,还是类型3,接着模型会进行纠正,每个数据点簇的平均值应该位于中间,因此模型会通过计算新的平均值来自我纠正。经过多轮的预测、纠正、预测、纠正,最后完成分类。
简单地说,K-means 聚类算法根据数据点与平均值的接近程度来预测花卉的类别。在迭代中,根据预测标签与数据的拟合程度更新 K 个聚类。
照片分类:表征学习
如果我们想对照片进行分类,我们依然思考相同的两个问题。
第一,我们如何测量?这里有多少绿色植物?它有鼻子和毛吗?要让计算机进行这些观察,我们需要测量每张图像中的数千个红色、绿色和蓝色像素。
第二,我们如何表示?对于鸢尾花分类来说,只需要花瓣长度和宽度两个维度的平均值即可,但是照片分类这样做似乎行不通。
我们需要模型来创建一个表示,告诉我们两幅图像是否相似。数据中存在比单个像素更抽象的有意义的模式,在多张图像中寻找这些模式被称为 表征学习(Representation Learning)。这些模式帮助我们理解图像的内容以及如何将它们相互比较。表征学习在监督学习模型和无监督学习模型中都存在,因此我们可以有标签或没有标签地进行表征学习,从而发现世界中的模式。
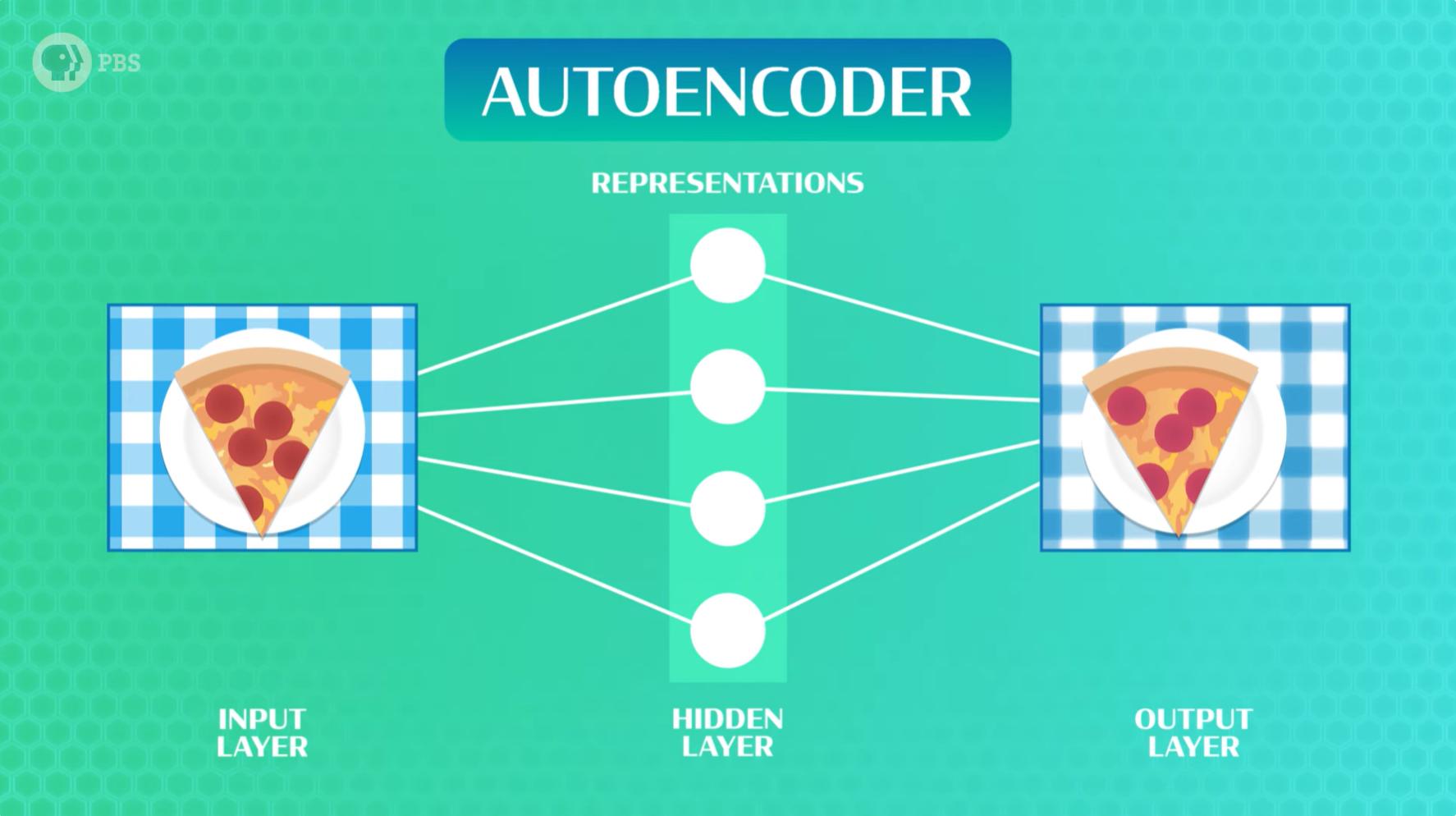
就像让你看一张披萨的图片,然后凭记忆画出来一样,对于AI来说,进行重建意味着生成所有正确的像素值。对于图像,我们将学习图像表示(而不是像花卉分类那样使用平均值),然后进行自我纠正。我们需要根据重建结果更新模型的“内部表示”。也就是说,随着我们对它进行更多训练,重建结果会越来越准确。
有多种方法将无监督学习与表征学习结合使用,让人工智能比较图像。例如,有一种叫做 自编码器(autoencoder) 的神经网络,它使用相同的权重和偏差的基本原理来处理输入,将数据传递到隐藏的神经元层,最后传递到预测输出层。换句话说,输入是一张图像,隐藏层包含表示,输出是原始图像的完整重建。
人工智能将如何实现其宏伟目标?
我们都知道,无监督学习是最终答案。 —— 图灵奖得主 Yann LeCun(杨立昆),2018
P7 自然语言处理(NLP)
自然语言处理(NLP,Natural Language Processing)主要探索两个核心概念。首先是自然语言理解,即如何从字母组合中理解含义(例如在淘宝商城输入“苹果”,它会为你搜索iPhone或真正的苹果),其次是自然语言生成,即如何从知识中生成语言(例如谷歌翻译、或聊天机器人chatGPT)。
处理自然语言非常棘手,因为同一个词如果没有上下文和语义语境,可能有不同的意思。例如“bank”可以指“银行”,也可以是“河岸”。甚至同一个词说出来的语调不一样,含义都可能不同。从小到大,没有人告诉我们猫是一种柔软的、会发出呼噜声的、会追老鼠的动物,但当我们还是孩子的时候,可能有人告诉我们“这是一只猫”,于是我们认识了猫。
分布语义和计数向量
自然语言当中有太多的近义词、同义词,一种常见的判断词语含义是否相似的方法是使用 分布语义(distributional semantics),即观察哪些词语经常出现在同一句子中。正如语言学家约翰·弗斯(John Firth)所说:“通过一个词所搭配的词语,你就能了解一个词的含义”。
为了让计算机理解分布语义,我们必须用数学来表达这个概念。一种简单的技巧是使用 计数向量(count vectors)。计数向量是指一个词与其他常用词在同一篇文章或句子中出现的次数。如果两个词出现在同一个句子中,它们的含义很可能非常相似。计数向量的问题是我们需要存储大量数据,也就是说,我们需要一个庞大的列表,其中包含我们曾经在同一句子中见过的所有单词,显然,这一点都不好管理。
编码器-解码器模型
因此,我们希望学习一种单词表示,它能够捕捉所有相同或相似的关系,但要更紧凑。我们很快想到无监督学习,我们需要一个能够构建内部表示并生成预测的模型,这被称为 编码器-解码器模型(encoder-decoder model)。编码器告诉我们应该思考什么,记住我们刚刚读到的内容,解码器则利用这些想法来决定要说什么或做什么。
如果我有这样一句话:「我有点饿了,我想吃点巧克力_____。」最有可能填入空格的词是什么?我们该如何训练一个模型来编码这句话,并解码空格处的猜测?在这个例子中,我们猜答案可能是“蛋糕”或“牛奶”,但不太可能是“土豆”,因为我们从未听说过“巧克力土豆”。能够填入空白处的词组是一个无监督聚类,AI可以利用它。因此,对于这句话,我们的编码器可能只需要关注单词“巧克力”,这样解码器就能从“巧克力[食品]”的词组中提取词来填空。
另一个更难的句子是:「我的朋友黛安娜来自圣地亚哥,她非常喜欢物理,她下周要过生日,所以我想找一份礼物送给____。」当我读到这句话时,我的大脑识别并记住了两件事:第一,我们正在谈论20个词之前的「黛安娜」,第二,我的朋友黛安娜使用了代词“她”。这意味着我们希望编码器构建一个表示,捕捉句子中所有这些信息,以便解码器能够选择正确的词来填空。
继续看另一个句子:「我的朋友黛安娜来自圣地亚哥,她非常喜欢物理,她下周要过生日,所以我想给她找一份礼物,这份礼物要和_____有关。」,要填入正确的答案“物理”,说明模型构建的表征必须记住整句话的关键细节,要知道,模型能够记住的信息量是有限的。
循环神经网络(RNN)
让我们尝试用神经网络预测句子中的下一个词,我们可以从书籍或音视频中获得大量的语言数据,以此来训练我们的模型。首先,我们需要定义编码器,也就是一个能够读取输入的模型(例如,输入一个句子)。这需要用到一种称为 循环神经网络(Recurrent Neural Network,RNN) 的神经网络。RNN内部有一个循环,使其能够重用单个隐藏层,该隐藏层会随着模型一次读取一个单词而更新,然后,模型会逐渐构建起对整个句子的理解,包括哪些单词在句首或句末,哪些单词修饰其他单词,以及许多其他与语义相关的语法属性。
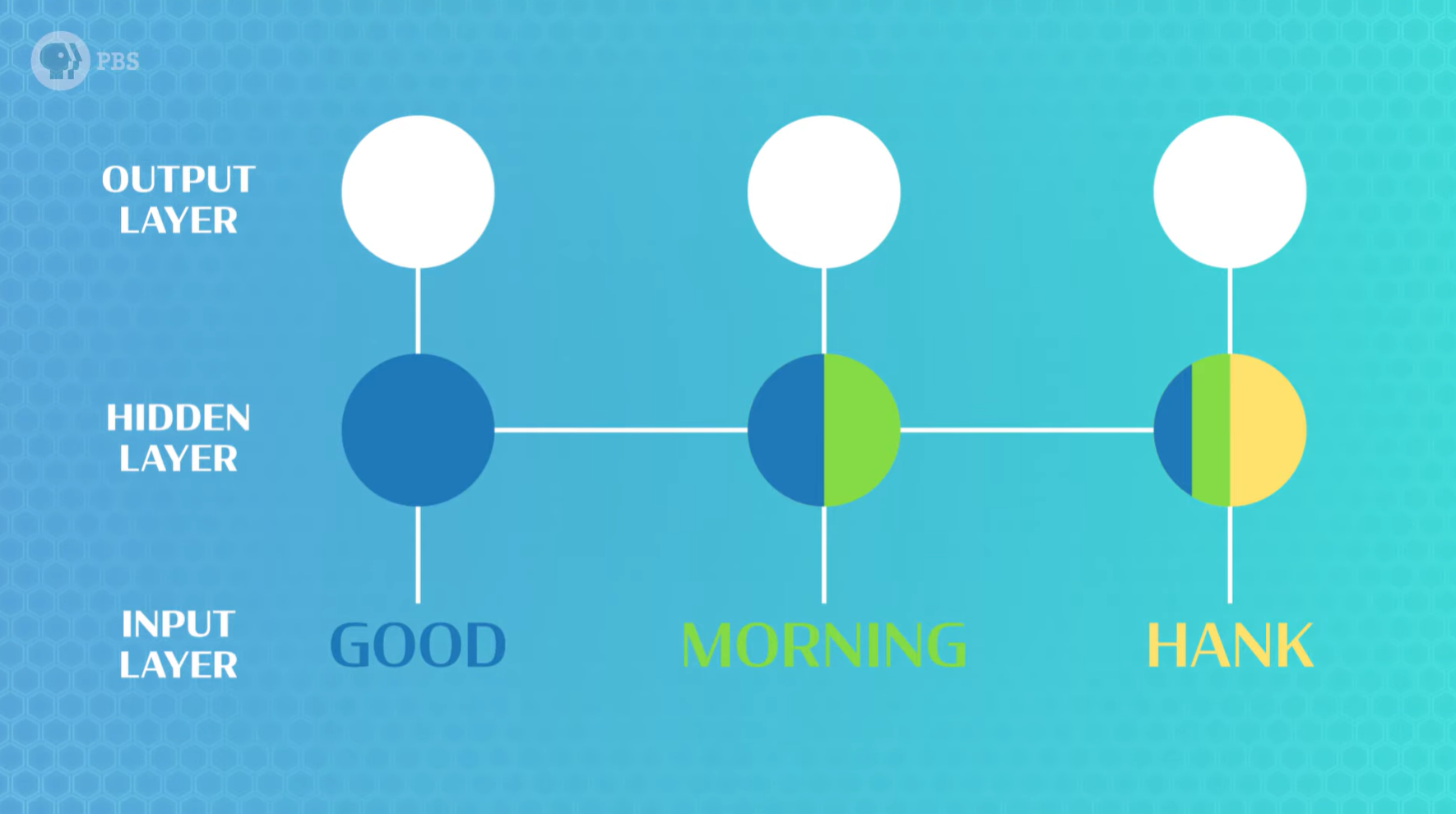
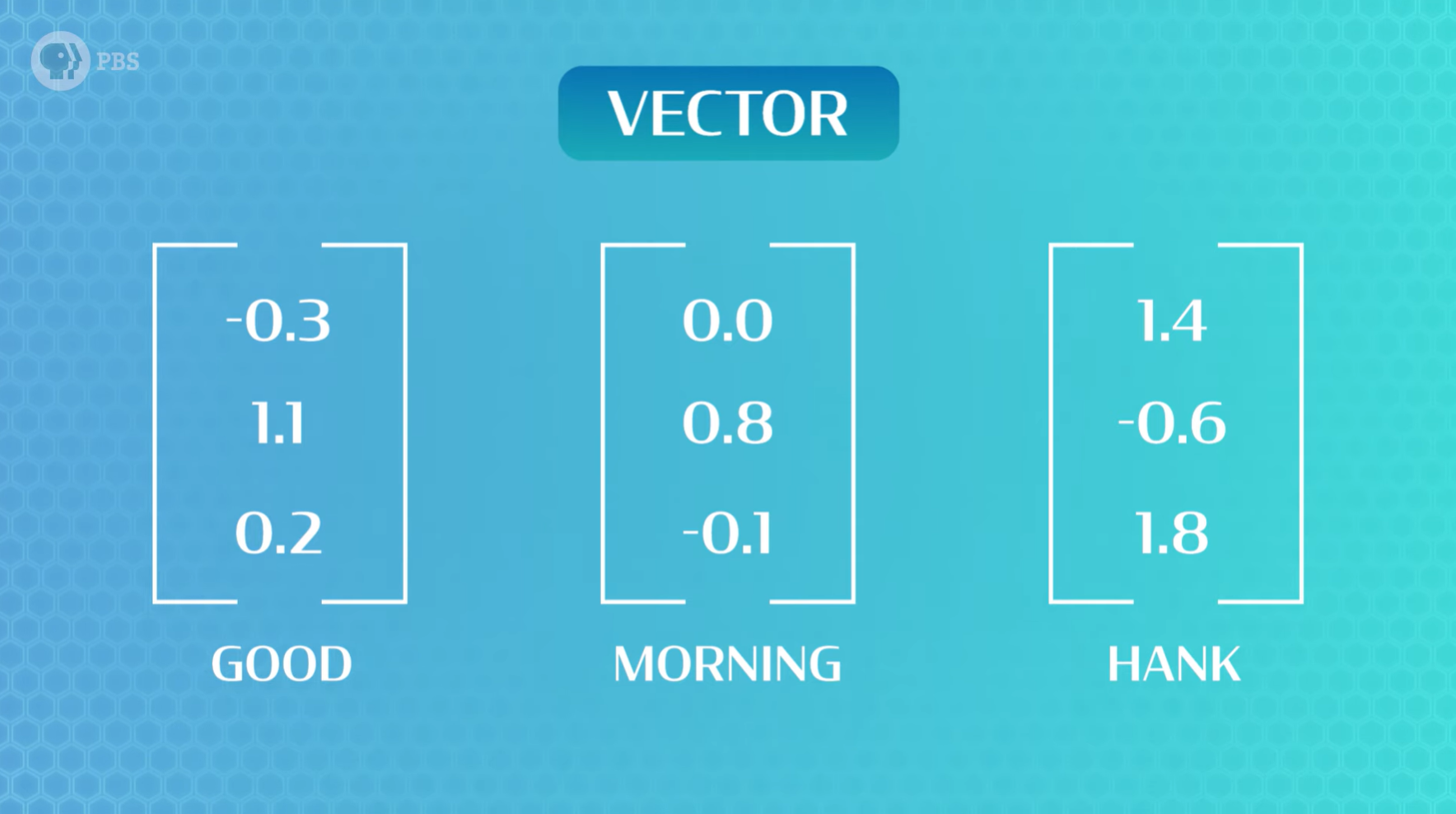
我们不能直接将单词放入网络中,我们也没有可以轻松测量并提供给模型的特征。因此,我们要求模型自行学习单词的正确表示(这就是无监督学习的用武之地)。为此,我们首先为每个单词分配一个随机表示(在本例中,是一个称为向量的随机数字列表),接下来,我们的编码器将接收所有这些表示,并将它们组合成一个单一的共享的表示,用于整个句子。
此时,我们的表示可能毫无意义,但为了训练循环神经网络 (RNN),我们需要它进行预测。对于这个特定问题,我们将考虑一个非常简单的解码器,一个单层网络,它接收句子表示向量,然后输出词汇表中每个可能的单词的分数。随后可以将得分最高的单词解释为我们模型的预测结果。再然后,我们可以使用反向传播来训练RNN。
因此,通过训练模型预测下一个单词,模型可以学习 编码器RNN 和 解码器预测层 的权重,并改变我们最初赋予每个单词的随机表示。也就是说,如果两个单词的意思相似,模型会使它们的向量更加相似。谷歌的研究人员训练过一些词语表示,我们发现“巧克力”附近有很多食物比如可可和糖果,相比之下,与“物理学”表征相似的词语有牛顿和宇宙。整个过程使用了无监督学习,它为我们提供了一种学习一些非常有趣的语言表征和词簇的基本方法。
接收句子的一部分并预测下一个词只是自然语言处理 (NLP) 的冰山一角。如果我们的模型接收英语并生成西班牙语,我们就拥有了一个翻译系统,如果我们的模型可以读取问题并生成答案,恭喜你,发明了chatGPT 。然而,训练也可能存在错误,例如,一个专注于学习烹饪知识的模型可能会认为玫瑰是糖霜做的,因为它见到太多的“玫瑰蛋糕”。
P8 实践课:构建一个语言模型
如何让AI像人类一样说话?实际上,现阶段的AI并不能理解任何东西,但AI通常非常擅长发现并复制某种模式。当我们教任何AI系统理解和生成语言时,我们实际上是在要求它在某些行为中发现并复制模式。因此,构建一个自然语言处理的AI,我们只需要创建一个模型,让它学习人类说话的方式,具体只需要分为四个步骤。
(本节配套实验代码:Games Lab: Crash Course AI #8)
步骤一:收集并清洗数据
如果你想让AI学习某个公共人物说话,就得想办法收集到这个人的语料,例如,从他的视频中提取字幕。数据收集通常是任何机器学习项目中最难、最慢的部分。收集到的数据也往往需要先进行预处理。记住,计算机只能处理数字,所以我们需要将句子拆分成单词,然后将单词转换成数字。单词很有用,但是单词出现多少次也可能很有用。
在这里,我们使用术语“词法类型(lexical type)”和“词法标记(lexical token)”。词法类型是指单词,而词法标记(下称token)是指单词的特定实例,包括任何重复项。例如,句子“[机器][学习][的][目标][是][制造][一台][学习][机器]”,我们有7个词语,但有9个token,因为“学习”和“机器”出现了2次。在 NLP 中, 分词(tokenization) 是将句子拆分成token列表的过程。
同样的,我们把数据集分为训练集和测试集。此外,我们还需要一些辅助代码来帮我们统计词语出现的次数,在英语中,还需要处理如将 it's 拆分为 it 和 's ,将时态、副词等归一的问题。当遇到生僻词时,可能在整个数据集中只出现一次,这种AI难以学习,可以统一替换为“unk”或未知(在大语言模型中这个问题则不存在)。
(请参考配套实验代码1.x部分)
步骤二:搭建模型
首先,我们需要将句子转换成数字列表。我们希望每个词汇类型对应一个词,所以我们将创建一个字典,为词汇表中的每个词分配一个数字。然后将数据分成多个批次,以便模型并行读取。
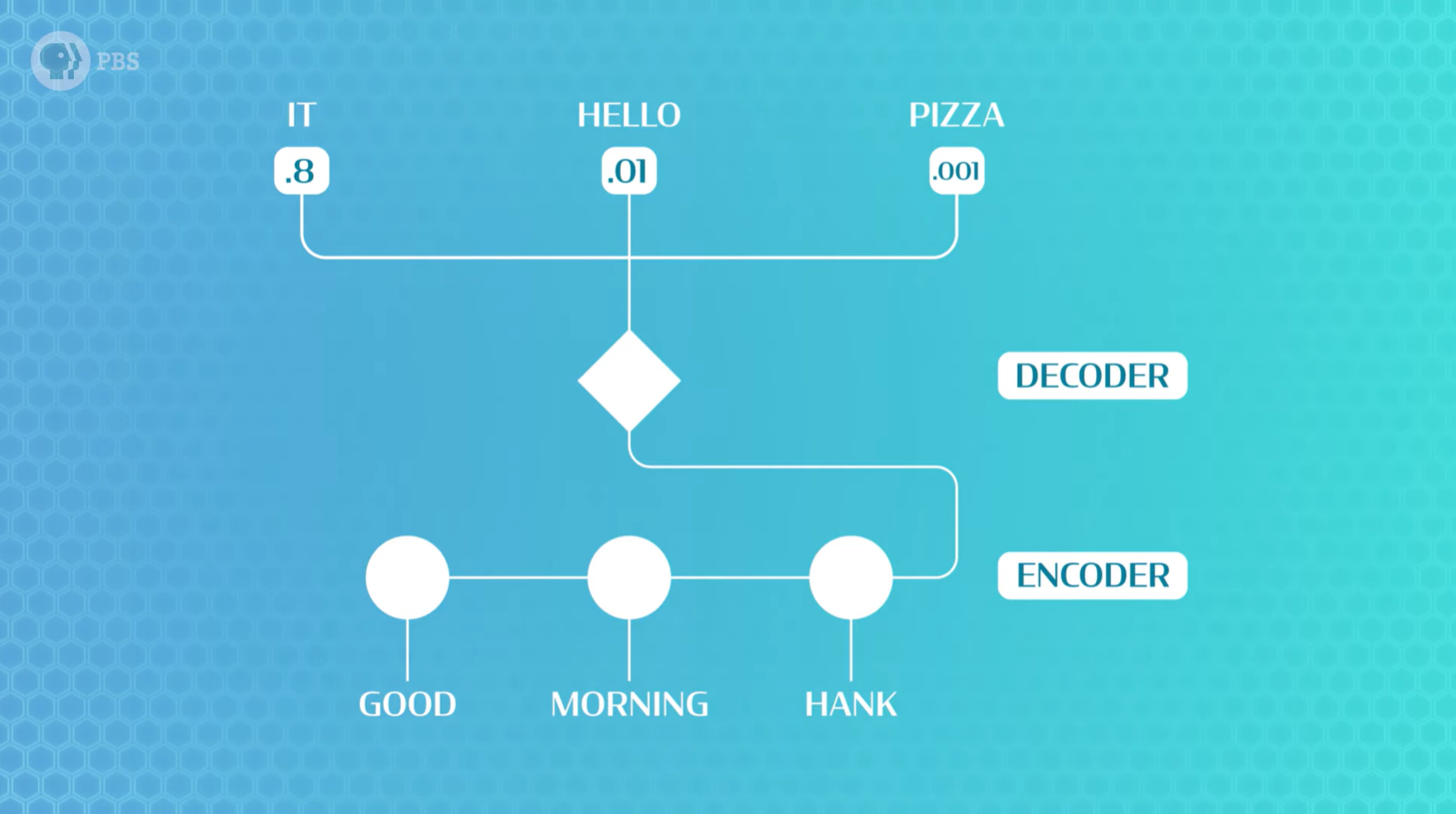
很明显,这是一个“编码器-解码器”框架的模型,该模型的核心逻辑是:接收几个单词,并尝试补全句子的其余部分。这需要两个关键部分:嵌入矩阵(embedding matrix) 和 循环神经网络 (RNN)。
嵌入矩阵是一个包含大量向量的列表,本质上是一个包含大量数字的表格,其中每一行对应一个不同的单词。这些向量行记录了两个单词之间的关联程度。这意味着如果两个单词的用法相似,那么它们在向量中的数字应该相似,但是,一开始这些都是随机的。在我们的嵌入矩阵里,单词变成了索引,索引又变成了向量。

接下来,RNN会通过一次融入一个新单词来逐步构建隐藏的表征。根据任务的不同,RNN 会以不同的方式组合新知识,在读取句子中到目前为止的最后一个词输出后,我们将用它来预测下一个词。
(请参考配套实验代码2.x部分)
步骤三:训练模型
我们把不同批次的数据组合起来,遍历我们的数据集,并对每个样本运行反向传播算法来训练模型的权重。在一个训练周期内,网络将循环遍历每个数据批次——读取数据、构建表示、预测下一个词,然后更新它的预测结果。
随着模型的学习,它会意识到下一个词的好选择越来越少。困惑度(perplexity) 衡量的是模型缩小选择范围的效果,可以理解为模型在预测出正确答案之前平均进行的猜测次数。这个值越小越好。
(请参考配套实验代码3.x部分)
步骤四:进行推理
我们通常认为模型输出的是一个标签或预测,但实际上,神经网络会生成一系列分数或概率。最有可能的词具有最高的概率。因为我们在每一步都会得到概率,所以我们不必每次都选择最佳概率来生成一个句子,而是可以抽取3个词,并生成3个新句子。这3个句子中的每一个都可以生成3个新句子……然后我们就得到了一个可能性的分支图。
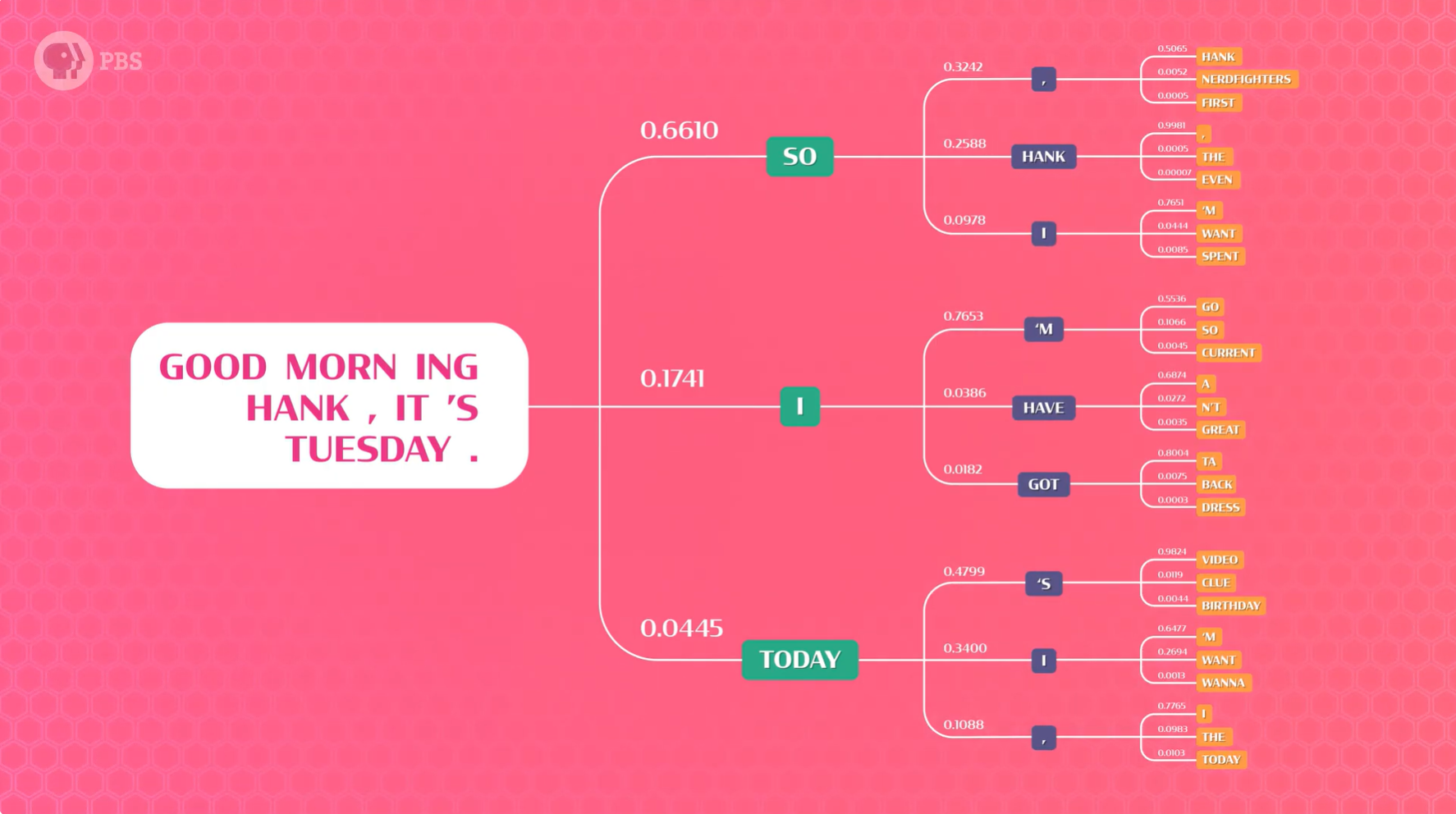
推理之所以如此重要,是因为我们想要的是一个真正优秀的句子,但模型一次只能告诉我们一个词的得分。所以我们要的是句子分支的总得分,而不是单个单词的得分。因此我们会需要一个 基本采样器(basic sampler) 来对每个完整句子的概率结果进行排序,从而看出哪些句子整体质量最佳。
如果每次都选择概率最高的单词得到的句子,结果可能是下面这样的,相信我,这不是你想要的。
早上好,汉克,今天是星期二。我会像这样,我会像这样,我会像这样,我会像这样……
(请参考配套实验代码4.x部分)
P9 强化学习(Reinforcement Learning)
我们通过反复试验来学习很多东西,这种通过“边做边学”来实现复杂目标的方法,称为 强化学习。
我们擅长走路,但要解释走路的过程就有点困难了,那就干脆不要解释,我们只需要在AI执行任务结束(或中间节点)时告诉它们是否成功,然后让AI告诉我们是如何做到的就行了。例如,我们想让AI学习走路,我们会在它站立并向前移动时给予奖励,然后找出它走到这一步所采取的步骤。AI站立和向前移动的时间越长,它行走的时间就越长,获得的奖励也就越多。所以,强化学习的关键在于反复试错。谷歌 DeepMind 就是使用强化学习教AI机器人行走、跳跃,甚至躲避障碍物,并取得了一些令人印象深刻的成果。
积分分配
在监督学习中,每次动作之后,我们都会有一个训练标签,告诉AI它是否做对了。但在强化学习中,我们无法做到这一点,因为在它完全完成任务之前,我们不知道什么是“正确”的。强化学习其中一个最难的部分称为 积分分配(credit assignment)。很难知道哪些动作是有帮助的(应该获得积分),以及哪些动作是无益的(减慢了AI的速度),因为我们不会在每次动作后停下来思考。
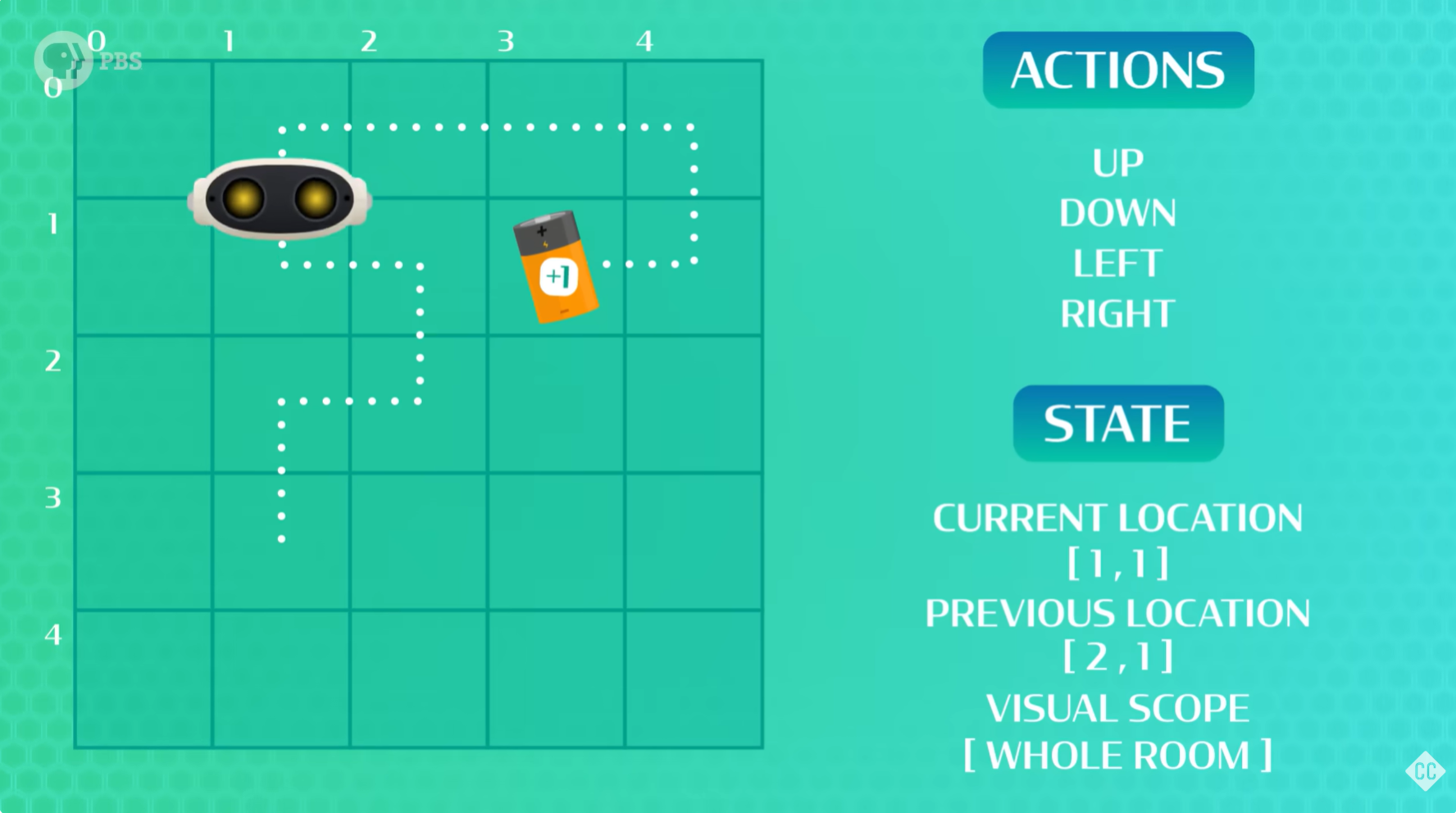
智能体(agent)会与周围环境进行一段时间的交互,无论是游戏棋盘、虚拟迷宫,还是现实生活中的厨房,我们会在它赢得游戏时给予奖励。每次智能体获胜时,我们都可以回顾它所采取的动作,并慢慢弄清楚哪些游戏状态是有帮助的,哪些是无益的。在这个反思过程中,我们为这些不同的游戏状态分配价值(value),并决定哪些动作效果最佳的策略。
回顾智能体走过的路径,并给他走过的所有单元格赋予一个值。具体来说,靠近目标的单元格值更高,而距离目标较远的单元格值更低。这些值有助于强化学习的试错,并且为我们的智能体提供了更多信息,以便在它再次尝试时采取更好的行动!

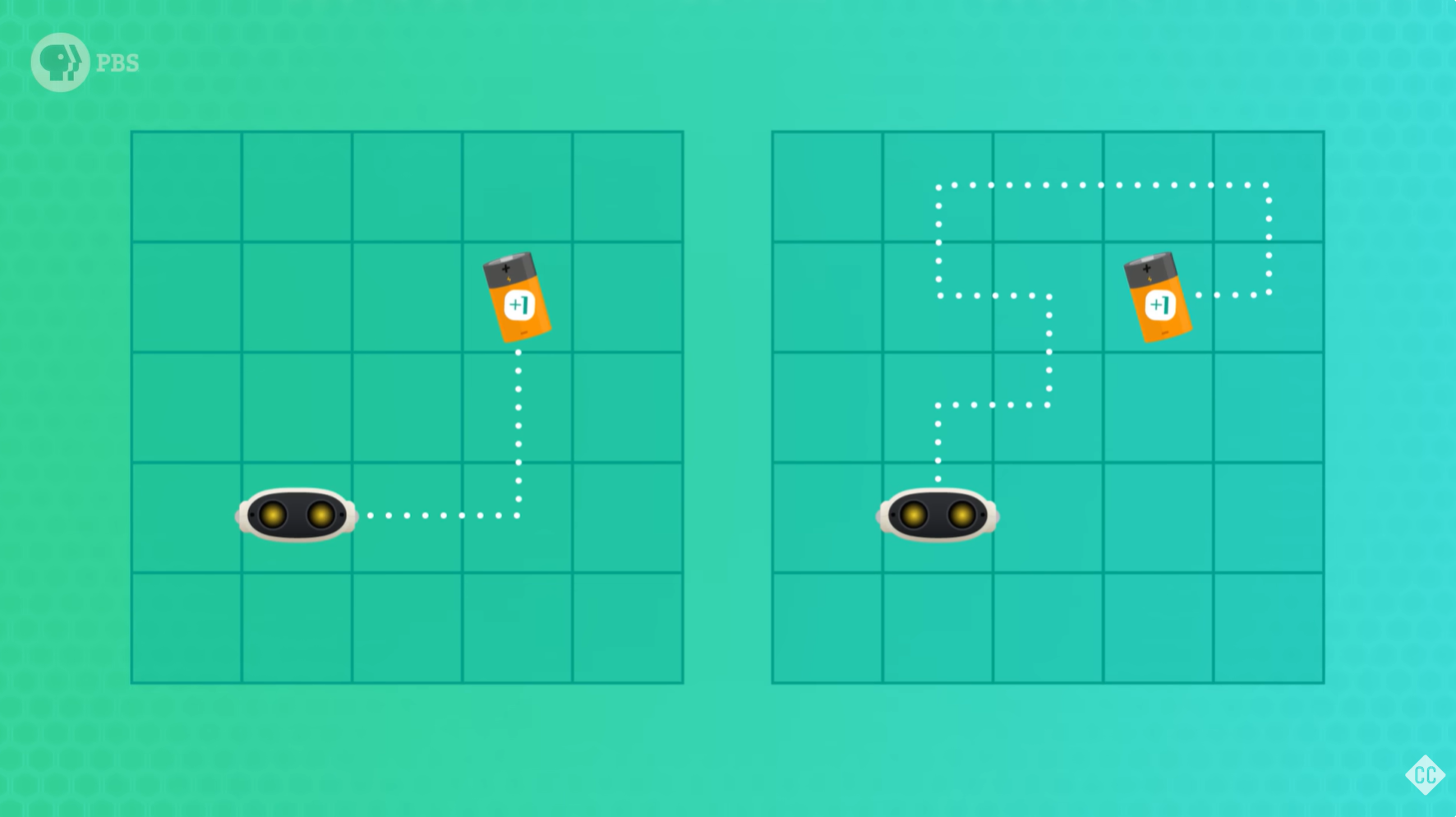
权衡利用和探索
强化学习中有一个重要的概念是 利用和探索之间的权衡(trade-off between exploitation and exploration)。AI已经探索出一条可行的路径了,下一次它完全可以继续走条路(利用),但是我们会希望它继续寻找更好的路径(探索)。我们可能会让它继续走不同的 100 次,在他每完成 1 次后就更新他去过的单元格的值,最后看看最优的那一条是什么。当然,环境可能改变,如果我们每天回家走的路正在施工,我们不得不绕道而行,这正是强化学习问题变得更有趣,但也更难的地方。
深度强化学习在大规模计算上的应用,取得了非常令人瞩目的成果。这些系统可以探索庞大的环境和大量的状态,从而实现AI学会玩游戏、下围棋等成果。许多此类问题的核心是离散符号,例如前进的指令或游戏棋盘上的方格,因此如何在这些空间中进行推理和规划是人工智能的关键部分。
P10 符号人工智能(Symbolic AI)
早在1959年,计算机科学家就构想过“通用问题求解器(General Problem Solver)”的程序,他们希望把问题的内容与问题解决的技巧分开来思考。例如,无论我们从哪里出发,想要去哪里,我们的大脑都会使用相同的基本推理策略来规划最佳路线。计算机是运用数学进行计算的逻辑机器,因此,逻辑显然是“通用问题求解器”这类问题解决技术的理想选择。
在通用问题求解器中,他们将现实世界的物体表示为符号,这就是 符号人工智能(Symbolic AI) 一词的由来,如今,某些AI系统正是通过这种方式做出决策、生成计划并表现出“思考”的能力。
逻辑和符号
符号人工智能(或者叫经典AI,符号主义AI),跟现代神经网络使用大量数据训练模型,并利用最佳猜测和概率来预测答案的做法不同,它无需训练,无需海量数据,也无需猜测,只需要用符号来表示问题,然后用逻辑来寻找解决方案,因此我们只需将我们关心的整个宇宙用符号表示到计算机中即可。总而言之,逻辑是我们解决问题的技术,而符号是我们用来表示计算机中问题的方式。
例如,如果我们想表示一个巧克力甜甜圈,我们可以写成 巧克力(甜甜圈),杰瑞吃一个甜甜圈,我们会写成 吃(杰瑞, 甜甜圈),因为这能描述一个符号与另一个符号之间的关系。我们可以将符号视为名词,将关系视为形容词或动词,它们描述符号如何协同工作。一个关系可以描述任意数量的符号。
知识库
我们将包含宇宙所有真理的集合称为 知识库(knowledge base),我们可以使用逻辑仔细检查我们的知识库,以便回答问题并利用人工智能发现新事物。这基本上就是 Siri 的工作原理,Siri 维护着一个庞大的符号知识库,所以当我们问她问题时,她会识别名词和动词,将名词转换成符号,将动词转换成关系,然后在知识库中查找它们。
例如,“杰瑞开着一辆又臭又旧的车。”,这句话的符号是 杰瑞 和 车,关系则是 开、臭、旧,然后我们就可以用逻辑连接词 AND、OR、NOT 把这些符号组合起来,构成句子(命题),再利用命题逻辑的规则和真值表来确定这些命题是真还是假。也就是说,在这个例子中,如果这辆车确实很臭,而且很旧,并且杰瑞真的在开这辆车,那么命题就为真。
在计算机中,可以把假的关系看作数字0,把真的关系看作非0的任何数字,把AND运算看作乘法,把OR运算看作加法,把NOT运算看作取反。那么,如果这辆车不臭,或者不旧,或者开车的不是杰瑞,那么整个命题就为假了。
推理
现代符号AI系统每秒可以模拟数十亿个“如果/那么”语句!利用命题逻辑的基本规则,我们可以开始构建一个知识库,其中包含所有关于我们宇宙的真命题。构建好这个知识库之后,我们可以使用符号AI来回答问题并发现新事物!可是,这个世界真命题那么多,哪里构建得完?幸运的是,计算机非常擅长解决逻辑问题。因此,如果我们用一些命题填充知识库,那么程序就可以找到新的符合知识库逻辑的命题,而无需人类逐一告知。
像这样,提出新命题并检查它们是否符合知识库逻辑的过程称为 推理(inference)。例如,如果把三明治定义为面包夹着肉的符号,那么,同样是面包夹着肉的热狗也会被推断为三明治,当三明治打折时,热狗也应该打折。
符号主义 or 联结主义 ?
多年来,一些AI系统为超市、银行、保险公司和其他行业创建了知识库,帮助他们做出重要决策。这些AI系统被称为 专家系统(expert systems),因为它们基本上取代了专家,例如保险代理人或信贷员。专家系统并非不如神经网络,主要原因有以下三点:
- 人类可以轻松地定义和重新定义专家系统中的命题逻辑,这意味着可调整
- 专家系统基于逻辑和推理得出结论,而不仅仅是像神经网络那样进行试错猜测,准确性高
- 专家系统可以通过展示哪些部分被评估为真或假来解释其决策,这帮助你了解为什么你的贷款申请被拒绝
但是,专家系统也有解决不了的问题,毕竟,这个世界不是严格的非真即假、非黑即白,现实世界是模糊且不确定的,人类的直觉几乎不可能用符号和命题逻辑来编程。
所以,世界需要符号主义(Symbolic),也需要联结主义(Connectionism)。