
Crash Course AI(1-5)
人工智能让量身定制成为可能。
课程地址:
全集笔记:
- Crash Course AI(1-5)
- Crash Course AI(5-10)
- Crash Course AI(11-15)
- Crash Course AI(16-20)
- Crash Course AI Future(1-5)
导论
这是 Youtube 上面 Crash Course 系列课程关于人工智能的科普课程,适合所有人学习(不需要计算机背景)。这门课不是研究具体AI理论或算法的,也没有复杂高深的数学公式和推理过程,学完这门课更无法让你获得一个AI研究员相关的岗位。这门课的作用在于让你了解什么是人工智能,它包括哪些概念,例如什么是监督学习和无监督学习,什么是神经网络,什么是自然语言处理……因此,这门课的重点在于帮助你了解人工智能相关的概念和基础的原理。
这样,在当前AI时代的浪潮下,不至于成为新时代的“文盲”,学习一点AI知识,在未来AI的机遇面前,也许你就能比别人想得更远一步。
注意,这门课上线于2019年,彼时像 chatGPT、Deepseek 等还未被发明出来,因此本课程会缺失这两年兴起的AI应用及其原理(Transformer和注意力机制)相关的介绍,好在 Crash Course 于2025年上线了 Crash Course AI Future 课程,对最新的AI进行了介绍,两门课可以连着一起看。我们也因此不得不感叹,AI发展速度如此之快。
P1 什么是人工智能(AI)?
一台机器能够解读数据,并有可能从数据中学习,并利用这些知识来适应环境并实现特定目标,那么我们就称其拥有人工智能(AI,artificial intelligence)。
人工智能和自动化正在改变一切。这就像18世纪的工业革命,这种变革是全球性的,有些人对此感到兴奋,有些人则感到恐惧。但无论如何,我们都有责任了解人工智能,并思考它将在我们的生活中扮演怎样的角色。
当我们在超市或网上购物时,一种AI会为商超决定进货哪些商品以及进货数量,当我们浏览社交网站时,另一种AI会挑选广告推送给我们;买保险时一种AI可以帮助我们确定车险的保费,去银行贷款时另一种AI决定我们是否能贷到款。AI甚至会影响人生中的重大决定。
当前的AI本质上只是机器中的程序。我们需要给AI提供大量数据,并标记这些数据相关的信息(例如,对人类来说是否好吃,草莓显然是“是”,而香皂则是“否”),然后,AI需要一台足够强大的计算机来处理这些数据,理解所有数据的意义。
人工智能的概念在1956年提出,但受限于当时计算机的性能,一直到2010年左右,人工智能领域都处于“寒冬”之中。后来随着计算机计算能力和处理速度的提高,人工智能的发展才迎来大爆发。有了计算性能,我们还需要有大量的数据可以喂给AI进行学习,得益于互联网的发展,我们今天在在贴吧知乎高谈阔论、在B站抖音刷视频,在微博小红书点赞收藏,在淘宝京东购买零食,使用滴滴高德来打车,甚至是信用卡刷卡记录,几乎所有的活动都会产生数据。
正因为我们拥有海量数据和强大的计算来解读这些数据,我们说人工智能革命正在发生。学习 AI 知识,我们就能做出一些小的决策来引导人工智能革命,而不是感觉自己像是在坐一场我们并不情愿的过山车。
历史告诉我们,革命与其说是事件,不如说是过程。
P2 监督学习(Supervised Learning)
我们可以根据自己的经验不断调整我们的想法和行为,最终让我们做出各种各样的决策,这就是学习的过程。人工智能也需要学习,主要有三种方法:
- 监督学习(Supervised Learning):指利用训练标签进行学习的过程。这是人工智能领域应用最广泛的学习方式。
- 无监督学习(Unsupervised Learning):指在没有训练标签的情况下进行学习的过程。也可以称为聚类(clustering)或分组(grouping)。
- 强化学习(Reinforcement Learning):指在环境中通过行为的反馈进行学习的过程。就像孩子们学习走路一样,没有人告诉他们该怎么做,他们只能练习,跌跌撞撞,不断提高平衡能力,直到能够迈出下一步。
计算机科学家们尝试用一种称为监督学习的过程来帮助计算机像人类一样进行学习。
监督学习是指由一位知道正确答案的人(监督员)在学习过程中指出错误。正如我们之前所说,AI需要算力和数据才能学习。监督学习需要监督者先提供大量的训练示例,例如,给AI提供大量动物的图像,并用标签对其进行分类,比如“爬行动物”或“哺乳动物”。经过训练,AI应该能够正确地对以前从未见过的图像进行分类,例如将小猫的图片识别为“哺乳动物”。这其实就是AI将电子邮件自动划分为“重要邮件”还是“垃圾邮件”的原理。
灵感来源:大脑🧠
监督学习的灵感主要来源于人脑。我们的大脑中有数十亿个神经元,每个神经元都有三个基本部分:细胞体、树突和轴突。一个神经元的轴突与另一个神经元的树突之间由一个称为突触的小间隙隔开。神经元之间通过突触传递电信号进行交流。当一个神经元接收到来自其他神经元的信号时,其细胞体内的电能就会积聚,直到超过阈值。然后,电信号沿着轴突向下传递,并传递到另一个神经元——在那里一切又重复起来。
现代计算机对人工智能进行编程,使其像神经元一样运作。首先,人工神经元接收乘以不同权重的输入,这些权重对应于每个信号的强度。这些信号的阈值由一个称为偏置的特殊权重表示,可以通过调整偏置来提高或降低神经元的放电意愿。因此,所有输入值乘以其各自的权重,然后相加,并通过数学函数得到结果。在最简单的 AI 系统中,这种函数被称为阶跃函数,它只输出 0 或 1。如果总和小于偏置,则神经元将输出 0 (表示否),如果总和大于偏置,则神经元将输出 1 (表示是)。只要有足够的数据和监督标签,就可以训练 AI 对任何事物做出简单的决定:三角形、垃圾邮件、语言、电影类型,甚至是外形相似的食物。
甜甜圈和贝果
如果我们想让 AI 认识甜甜圈和贝果,我们可以用质量和直径作为信号维度。一开始 AI 一无所知,所以它有一个随机权重来表示质量、直径和偏差,之后,我们拿大量的甜甜圈和贝果的照片让 AI 猜测它是什么,AI 接收这些输入(质量和直径),将它们分别乘以各自的权重,然后将结果相加,如果总和大于偏置值,那么 AI 会判定为贝果,否则 AI 会判定为甜甜圈。如果它答错了,我们就告诉它错了,并让它通过一定的更新规则重新调整权重来帮助他学习,如果它答对了,那么更新规则就是0,即权重不变。这样,随着它不断犯错并被不断更正,权重值会往合理的方向调整。

精确率和召回率
衡量一个AI靠不靠谱的两个指标分别是 精确率(precision) 和 召回率(recall)。精确率告诉你,当AI识别出某种食物时,你应该有多信任它,例如在他说的10个甜甜圈中,有8个确实是甜甜圈,那么精确率为80%。召回率告诉你程序能找到多少你想要的东西,例如在25个甜甜圈中,他只正确识别了8个,所以召回率只有32%。
精确率和召回率取决于做出判断的标准,在上面的例子中,是直径和质量。显然,这不够理想,为了提高它的靠谱程度,也许我们应该增加更多的判断指标(例如,是否有种子或糖屑),一般来说,输入越多,准确率越高,但AI也需要更多的处理能力和时间来做决策。
理想的AI系统应该体积小、功能强大,并且拥有完美的精确率和召回率。弄清楚使用哪些标准是解决大多数人工智能挑战的关键。大多数AI处理的问题比将事物分类到两个类别之一要复杂得多。
P3 神经网络和深度学习(Neural Networks and Deep Learning)
上一节让AI认识甜甜圈和贝果的过程,只是一种模仿单个神经元的感知器,但是我们的大脑利用 1000 亿个神经元来做决定,这些神经元之间有数万亿个连接。如果我们把许多感知器连接起来,创建所谓的人工神经网络,我们就可以利用人工智能做更多更实际的事情。
图像识别
不久之前,人工智能领域的一大挑战是现实世界的图像识别,例如从猫中识别狗,从汽车中识别飞机,从船中识别汽车。2009年,李飞飞教授和其他研究人员公开了一个庞大的公共数据集,其中包含已标注的真实世界照片。他们把这个数据集命名为 ImageNet 。它包含约 1400 万张带标签的图片,涵盖了 2.1 万个嵌套名词进行分类(例如“狗”标签嵌套在“家畜”标签下,家畜”标签又嵌套在“动物”标签下)。他们借助互联网的力量让成千上万人帮忙标注数据。
2012年,一名叫 Alex Krizhevsky 的研究生决定将神经网络应用于 ImageNet ,并取名为 AlexNet 。AlexNet 运用了很多隐藏的图层,以及速度更快的计算硬件来处理神经网络所需要的数学运算,它的脱颖而出引发了神经网络研究的爆炸式增长。于是计算机科学家们开始将神经网络应用于图像识别以外的许多领域。
神经网络的架构
所有神经网络都由输入层、输出层以及中间任意数量的隐藏层组成。输入层是神经网络接收数据的地方,这些数据以数字形式表示。每个输入神经元代表一个单一特征,即数据的某种特性(例如,甜甜圈中的糖克数),实际上,几乎任何东西都可以转换成数字(例如,声音可以用声波的振幅来表示,色彩可以用GRB数字组合)。
如果我们试图给一张狗的图像贴上标签,那么每个特征就代表一个像素的信息。一旦特征有了数据,每个特征就会将其数值发送到下一层中的每个神经元,每个隐藏层神经元都会对接收到的所有数字进行数学组合。目标是衡量输入数据是否包含某些组成部分,例如 “是不是红色”、“是不是包含眼睛”、“是不是包含毛发”……隐藏层中的每个神经元都会进行一些稍微复杂的数学运算,并输出一个数字,然后,每个神经元将其编号发送给下一层中的每个神经元,下一层可能是另一个隐藏层或输出层。
输出层是将最终隐藏层的输出进行数学组合以解决问题的地方。输出神经元对应每个标签的概率,例如狗92%,汽车1%,意大利面2%,于是我们选择概率最高的答案。

神经网络看起来就像一个黑盒子,它进行数学运算并输出答案。通常我们在使用一个神经网络时,它已经经过训练,神经元具有数学公式可以查找图像中的特定组成部分(例如,狗的鼻梁顶部的弧度),如果这个神经元专注于这个特定的形状和位置,它可能并不关心其他地方发生了什么。因此,它会将大多数它不关心的特征值乘以 0 或接近 0,而关心的乘以一个正或负的权重。这个隐藏神经元会将来自输入神经元的所有加权值相加,并将结果压缩到 0 到 1 之间。最终的数字基本上代表了该神经元的猜测(例如,这是狗的鼻子)。而其他的神经元负责其他的部分,最终传递给下一层去寻找更复杂的成分。最终到达输出神经元做出最终的判断(例如,是狗的概率为93%)。
记住,当我们的特征越来越多,层数越来越多,神经网络所需要的做出的数学运算也就越多,计算起来也就需要更长时间。
生活中的神经网络
神经网络正被用于为我们的生活做出越来越多的决定。例如,银行通过用户行为检测和预防诈骗,医疗机构通过显微镜下的细胞图像判断患癌风险,抖音通过视频图像识别为你推荐标签。了解这一切是如何发生的,对于当今世界的人来说都非常重要。

P4 训练神经网络(Training Neural Networks)
神经网络主要由两部分组成:架构和权重。架构包括神经元及其连接。权重是一个用来微调神经元如何进行数学运算的数值。因此,如果神经网络出错,通常意味着权重没有正确调整,我们需要更新它们,以便下次能够做出更好的预测,为神经网络架构找到最佳权重的任务称为优化(optimization)。
神经网络使用一种称为反向传播的算法来确保所有导致错误的神经元的计算都得到调整。
预测游泳池人数
假如我们想预测游泳池下周会有多少人来,我们很容易想到通过历史人数和当天气温绘制成图表,从图中寻找规律来进行预测。一种可行的找规律方法是使用一种称为线性回归的优化策略。我们首先在图上画一条随机的直线,这条直线大致符合数据点,我们计算直线与每个数据点之间的距离,将所有距离加起来,即可得到误差。我们的目标是调整回归线,使误差尽可能小。我们希望这条线尽可能地拟合训练数据,所得结果称为最佳拟合线。最后,我们就可以用这条直线来预测在什么气温下会有多少人来游泳。
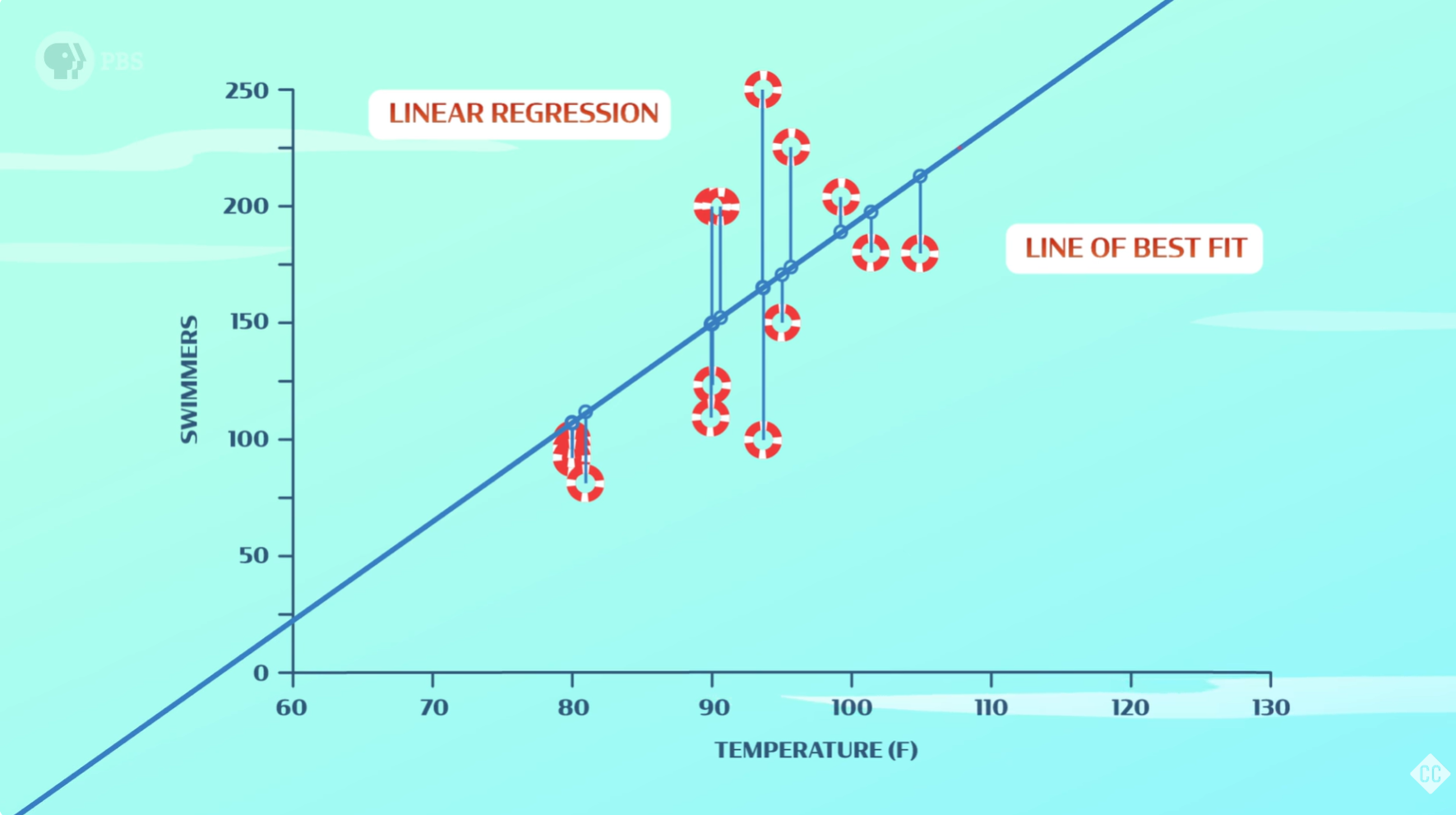
然而这里面有些不符合逻辑的地方。例如,在极冷的日子里,游泳池的人数是负数;而酷热难耐的日子里,游泳池的人数远远超过了游泳池的容纳能力。为了获得更准确的结果,我们可能需要考虑两个以上的特征(例如,温度和湿度),这时候,最佳拟合线就变成了最佳拟合平面,如果我们再添加一个特征(例如,降雨量),我们就无法进行可视化了。
可见,随着我们考虑更多特征,我们向图中添加更多维度,优化问题变得更加棘手,拟合训练数据也变得更加困难。
这时神经网络就派上用场了。我们可以把温度、湿度、降雨量等特征作为神经网络的输入层,游泳池人数作为输出层,并给定随机初始权重。然后用过去10天游泳池的大量测量数据来训练,神经元会将这些特征乘以权重,将结果相加,并将信息传递给隐藏层,直到输出神经元得到答案。
误差反向传播
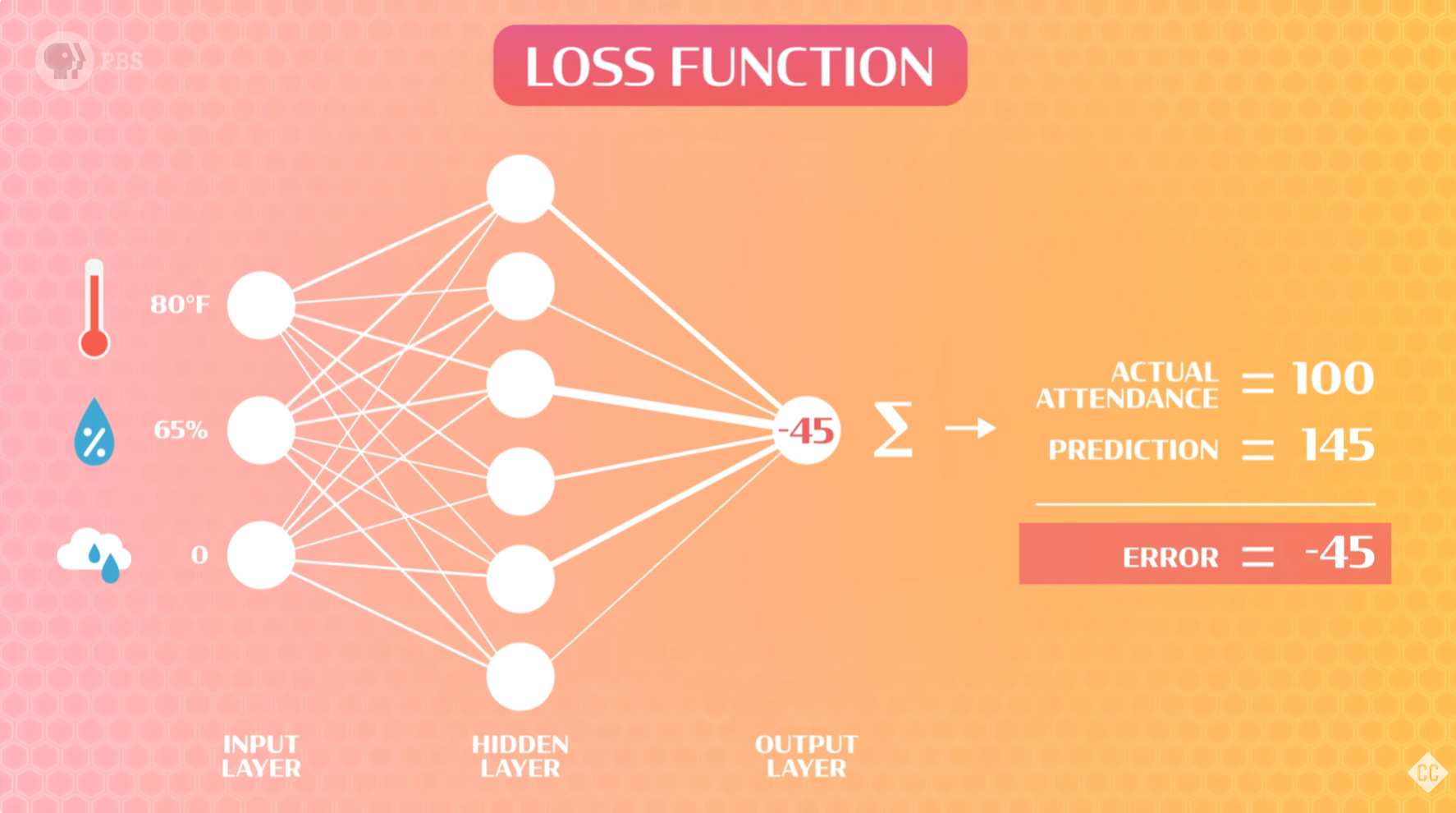
神经网络的输出和实际结果的差异就是误差,有时候神经网络的输出包含多个神经元,因此误差不仅仅是一个数字,我们用 损失函数(loss function) 来表示误差。
我们不断地调整权重,让神经网络的输出和实际结果尽量接近,但是神经网络这么复杂,层数这么深,怎么调整呢?科学家和数学家提出了一种称为 误差反向传播 的算法(简称反向传播)来查看损失函数。这个算法能够找出网络中出错的前几层的神经元,某些神经元的计算结果可能比其他神经元的计算结果更容易导致错误,因此它们的权重将进行更多调整。这些信息会反向传递,例如,输出神经元的误差会返回上一层,并调整应用于隐藏层神经元输出的权重,隐藏层神经元的误差会返回上一层,并调整应用于特征的权重。这就是反向传播思想的由来。
如果我们把误差比作一个山谷的最低点,我们当然希望越低越好。一开始,我们随机诞生在山谷地图的某一点,我们很容易想到往四周更低的方向走,直到不能再低。但是,在整个山谷你眼睛看不到的地方,可能存在更低点。这就是所谓的局部最优解但并非全局最优解。解决办法是多尝试不同的随机起始点,或干脆组建一支探险队,同时从不同的起始点出发,这样,总能找到全局最低点。我们甚至可以调整探险者的步长,让他们能够轻松地跨过小山丘,从而找到并下到山谷中。这个步长称为学习率(learning rate),它决定了每次反向传播时神经元权重的调整幅度。

防止过度拟合
当我们往神经网络中添加越来越多的特征(例如温度、湿度、降雨量、星期几、风速、游泳池周边蝴蝶数量、草的长度,甚至是救生员的绩点),我们总以为更多的数据就更有利于发现规律和提高准确性,但是,有时候反向传播算法过于擅长使神经网络适应某些数据,这可能会造成很大的问题,因为如果我们给神经网络一些不符合这些相关性的愚蠢新数据,那么它可能会犯一些奇怪的错误。这就是所谓过度拟合的危险。
防止过拟合的最简单方法就是保持神经网络的简单性。草的长度、蝴蝶的数量、救生员绩点,这些对游泳池人数的影响几乎是没有的,我们最好忽略这些特征。
所以训练神经网络不仅仅是一堆数学运算!我们需要考虑如何最好地将我们的各种问题表示为人工智能系统的特征,并仔细思考这些程序可能会犯哪些错误。
P5 实践课:如何让AI识别你的笔迹
为了让 AI 识别你的笔迹,我们把目标拆解为四个步骤。可参照右边完整的代码进行理解:Games Lab: Crash Course AI #5
步骤一:寻找数据集
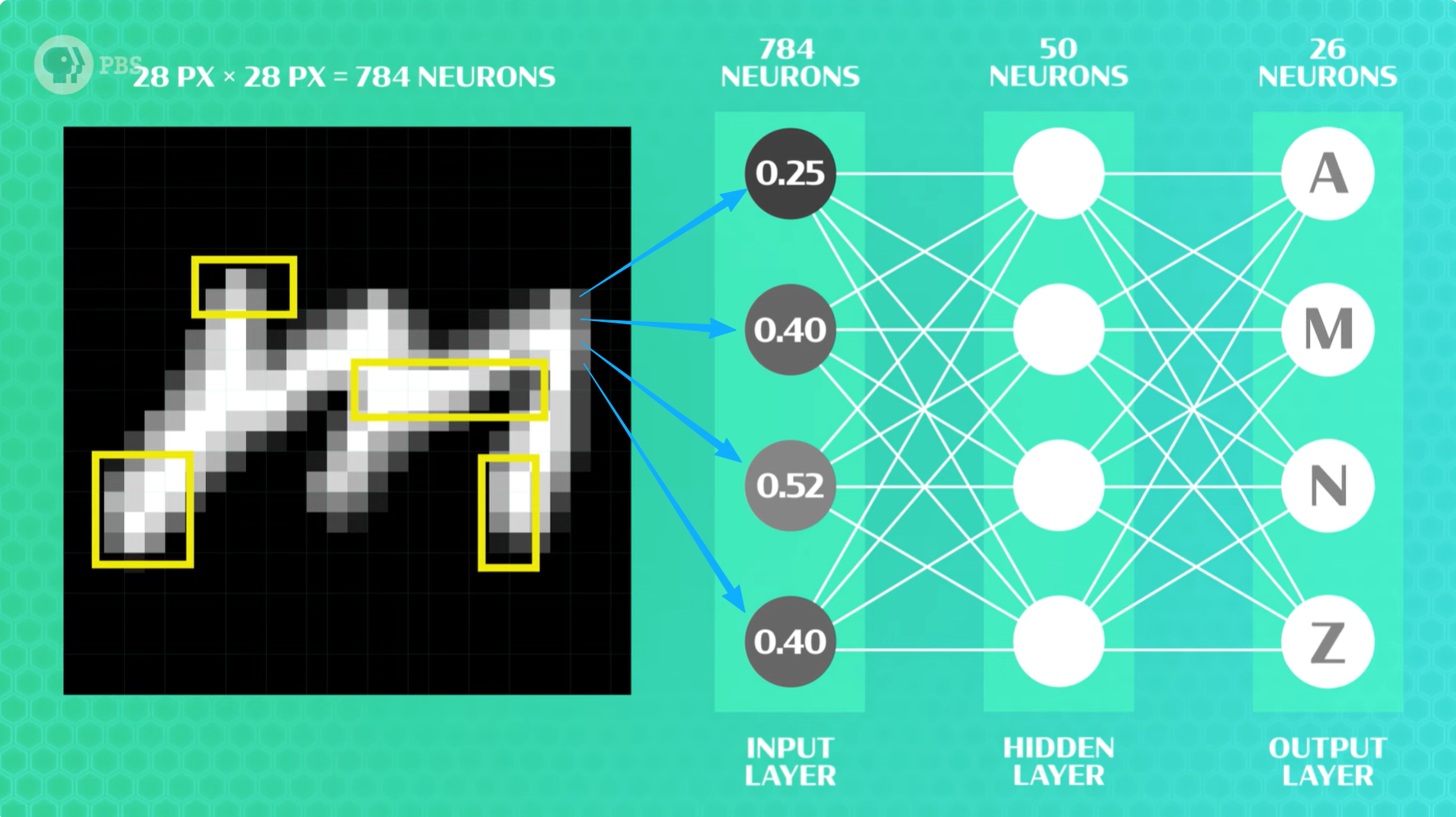
神经网络需要大量的标记数据来学习每个字母的大致形状。因此,第一步是先找到或创建一个带标签的数据集来训练我们的神经网络。自己创建一个带标签的数据集是一项巨大的挑战,我们最好先到网上看看有没有公开现成的。就笔迹识别来说,EMNIST就是一个现成的,该数据集包含数十万张标注的手写字母和数字图像,这些图像均来自美国人口普查表格。在 Python 中,只需要一行代码就可以导入整个数据集:
from emnist import extract_training_samples我们把数据集拆分为训练集和测试集。训练集用于训练神经网络,测试集是在训练过程中对神经网络隐藏的数据,后续可以用来检测它的准确性。数据集中的每一张图像都是 28x28 像素,灰度值介于 0 和 255之间,我们需要先对每个输入(在这个例子中是每一个像素)做归一化,即想办法得到一个介于 0 和 1 之间的数(在这个例子中是将灰度值除以255)。像这样对数据进行转换,使其更容易处理的机器学习方法称为预处理(preprocessing)。
并不是所有问题都有现成的数据集。如果我们尝试解决其他问题,我们就必须认真思考如何收集和标记数据来训练和测试我们的网络。数据收集是训练一个好的神经网络非常重要的一步!
步骤二:训练神经网络
创建神经网络,我们需要配置一个人工智能,它具有输入层、若干隐藏层,以及输出层。用专业一点的话来说,我们需要一个 多层感知器神经网络(MLP)。但我们不重复造轮子,在 Python 中可直接使用一个名为 SKLearn(Sci Kit Learn)的库,这个库包含许多不同的机器学习算法。
from sklearn.datasets import fetch_openml
from sklearn.neural_network import MLPClassifier
# This creates our first MLP with 1 hidden layer with 50 neurons
# and sets it to run through the data 20 times
mlp1 = MLPClassifier(hidden_layer_sizes=(50,), # 1个有50个神经元的隐藏层
max_iter=20, # 迭代20次
alpha=1e-4,
solver='sgd',
verbose=10,
tol=1e-4,
random_state=1,
learning_rate_init=.1)具体的过程如下图所示,输入层是每一个像素归一后的灰度值,中间的隐藏层是对某些特定区域的特征的识别,这里我们将参数调整为让1个有50个神经元的隐藏层迭代20次,最后的输出层是26个字母的概率。
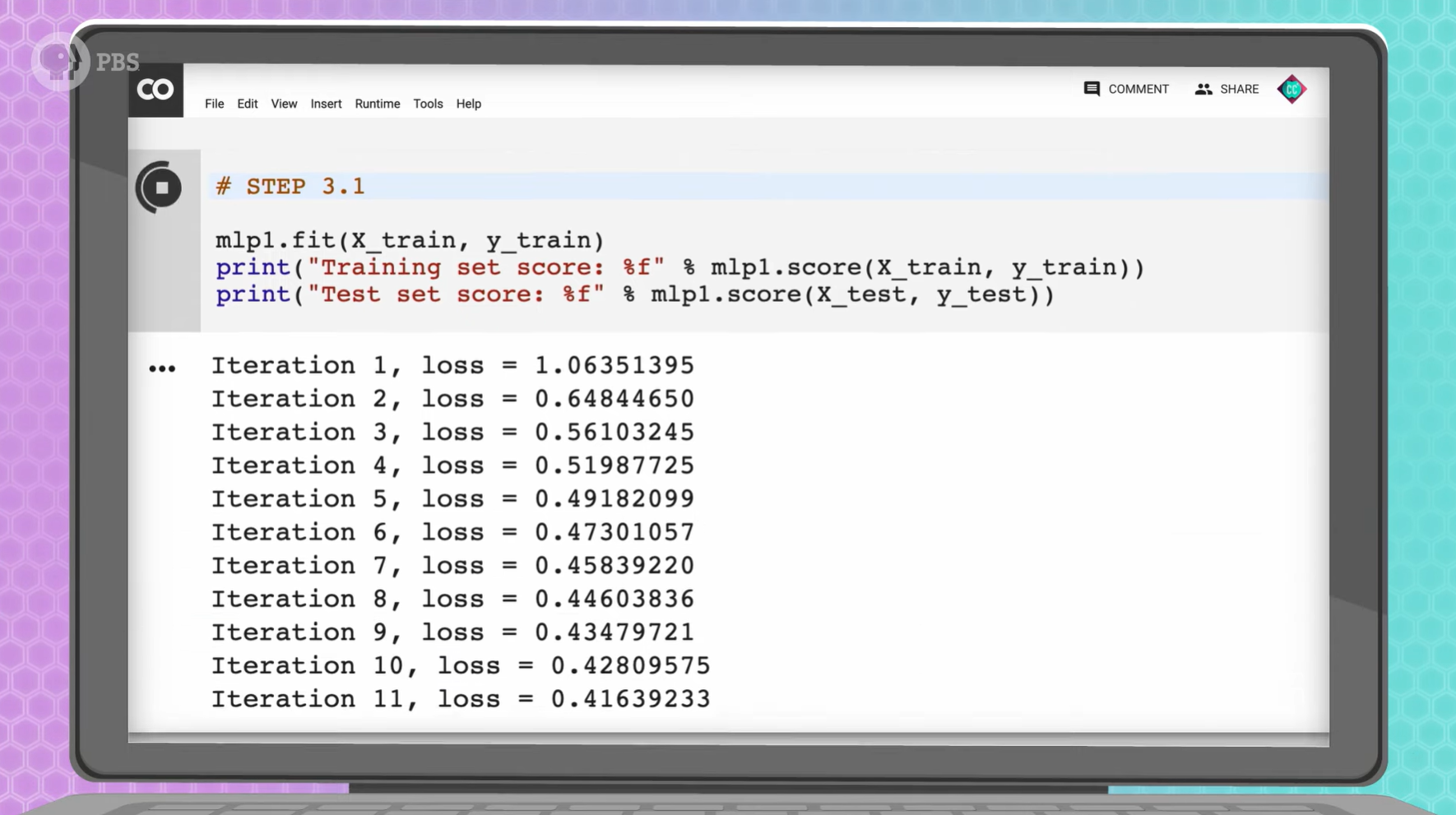
在处理完所有训练数据后,神经网络会将猜测结果和实际标签做比较,并更新权重和偏差。经过多次迭代,神经网络的预测结果应该会越来越好。即损失函数输出的误差越来越小。
步骤三:测试和调整
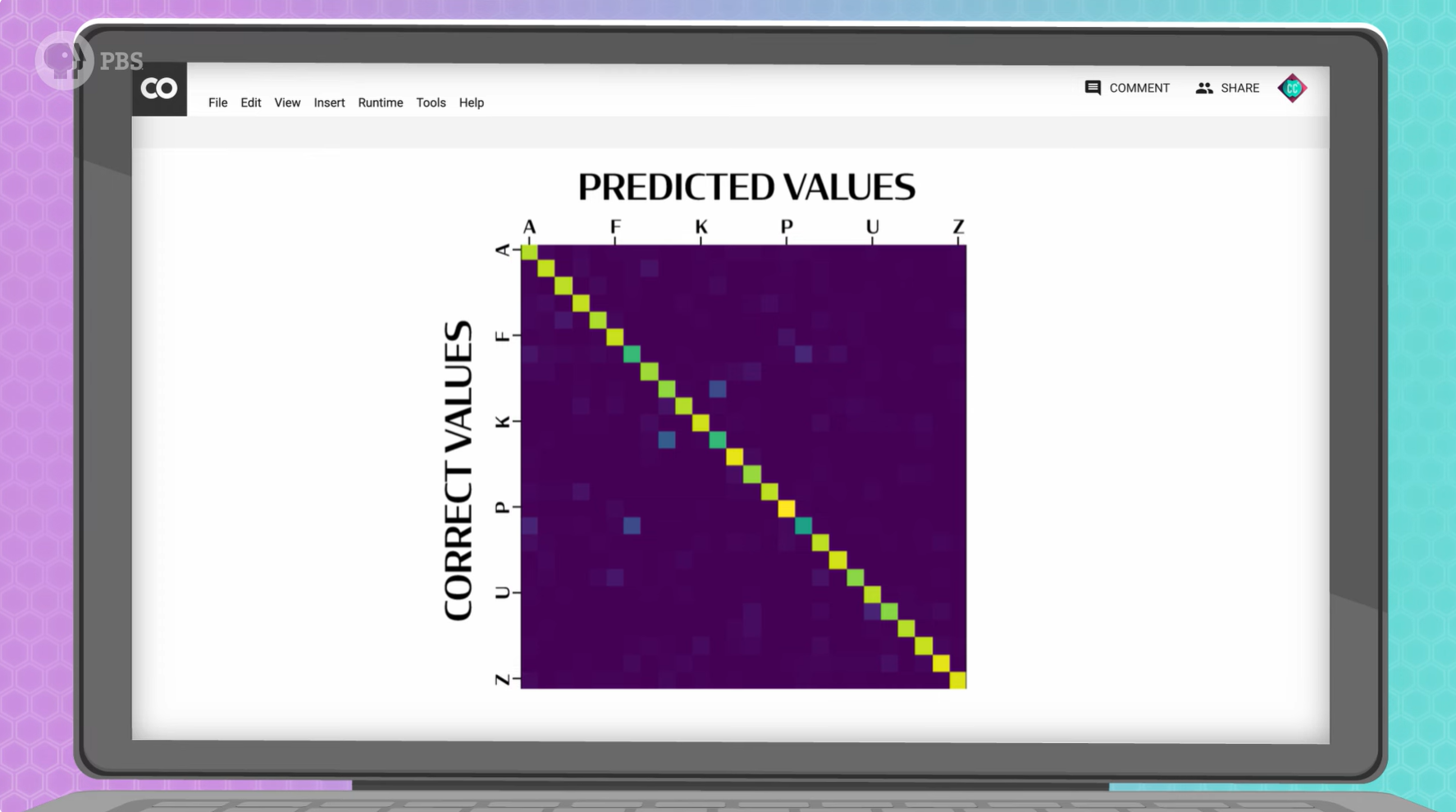
我们拿测试集的数据进行验证,看看 AI 能答对多少,混淆矩阵帮助我们直观地观察命中率,并思考可能的问题,例如,“L”和“I”太像了,导致这这两个字母命中率低。当我们对误差结果不满意,可以修改程序,例如增加训练轮数、增加隐藏层数、增加隐藏层中的神经元数量都可能有所帮助。代价是花费的时间会更久。
步骤四:验证
最后,我们拿我们真实的手写笔记图片(当然,只能包括英文字母和空格,因为我们没有训练中文),将其转换为跟刚刚训练的样本一样的格式(图片的像素大小,深底浅字还是浅底深字,用了什么图像滤镜等),并进行验证。
总而言之,最好是你的训练数据是怎么转换成特征参数的,实际数据也保持一致。否则可能会出现误差。