推荐系统漫游
参考教程:
参考书籍:
参考链接:
- Spark 官方文档- Collaborative Filtering
- Github项目 - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
- 在线图书推荐系统的实现(协同过滤)
- Github项目 - spark-book-recommender-system
常用的推荐算法
基于人口统计学的推荐(Demographic-Based Recommendation)
- 基本假设(underlying assumption):一个用户有可能会喜欢与其相似的用户所喜欢的Item
当我们需要对一个User进行个性化推荐时,利用User Profile计算其它用户与其之间的相似度,然后挑选出与其最相似的前K个用户,之后利用这些用户的购买和打分信息进行推荐。
基于内容的推荐(Content-Based Recommendation)
- 基本假设:一个用户可能会喜欢和他曾经喜欢过的Item相似的Item
比如你看了哈利波特I,基于内容的推荐算法发现哈利波特II-VI与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你。
基于内容的推荐引入了关于item的内容信息,来计算item与item之间的相似度。但跟用户历史行为无关。
- 优点:可以避免Item的冷启动问题
- 缺点:缺点一:推荐的Item可能会重复。典型例子:新闻。如果你看了一则关于MH370的新闻,很可能推荐的新闻和你浏览过的内容一致。缺点二:多媒体的推荐(音乐、电影、图片等)由于很难提内容特征,则很难进行推荐,一种解决方式则是人工给这些Item打标签。但是费时费力。
冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是基于内容的推荐算法可以分析Item之间的关系,实现推荐。
协同过滤的推荐(Collaborative Filtering Recommendation)
- 基本假设:用户A 和 用户B 如果对某些商品持有相同的观点,那么 用户A 跟 用户B 对 另一些商品 的观点会更接近。
协同过滤是指收集用户过去的行为以获得其对产品的显式或隐式信息。根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性、或者 用户的相关性,然后再基于这些关联性进行推荐。
基于协同过滤的推荐可以分为以下几个子类:
基于用户的协同过滤推荐(User-based Recommendation)
通过用户的行为信息,计算用户与用户之间的相似度。比如你跟你的朋友喜好类似,系统认为你们相似度高,如果你的朋友喜欢电影哈利波特I,那么就会推荐给你,这是最简单的基于用户的协同过滤算法。
基于物品的协同过滤推荐(Item-based Recommendation)
喜欢Item A 的用户,其可能也会喜欢与Item A相似的Item B。
相似度的计算是基于历史行为信息,计算每两个item之间的相似度(比如有多少人喜欢A,有多少人喜欢B,有多少人既喜欢A又喜欢B,A和B的相似度,就可以计算为共同喜欢A和B的用户个数除以喜欢A或喜欢B的总用户数)
我们可以简单比较下基于用户的协同过滤和基于项目的协同过滤:基于用户的协同过滤需要在线找用户和用户之间的相似度关系,计算复杂度肯定会比基于基于项目的协同过滤高。但是可以帮助用户找到新类别的有惊喜的物品。而基于项目的协同过滤,由于考虑的物品的相似性一段时间不会改变,因此可以很容易的离线计算,准确度一般也可以接受,但是推荐的多样性来说,就很难带给用户惊喜了。一般对于小型的推荐系统来说,基于项目的协同过滤肯定是主流。但是如果是大型的推荐系统来说,则可以考虑基于用户的协同过滤,当然更加可以考虑第三种类型,基于模型的协同过滤。
基于模型的协同过滤推荐(Model-based Recommendation)
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
比如说,有m个物品,n个用户的数据,只有部分用户和部分数据之间是有评分数据的,其它部分评分是空白,此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。
对于这个问题,用机器学习的思想来建模解决,主流的方法可以分为:用关联算法,聚类算法,分类算法,回归算法,矩阵分解,神经网络,图模型以及隐语义模型来解决。这种方法训练过程比较长,但是训练完成后,推荐过程比较快。
基于模型协同过滤的推荐机制是现今应用最为广泛的推荐机制。
优点:
- 它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的,所以这种方法也是领域无关的。
- 这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
缺点:
- 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
- 推荐的效果依赖于用户历史偏好数据的多少和准确性。
- 在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
- 对于一些特殊品味的用户不能给予很好的推荐。
- 由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
补充
协同过滤的本质是对用户喜好进行预测,其思想是根据邻居用户(与目标用户兴趣相似的用户)的偏好信息,计算出某用户对某商品的感兴趣度。
如果我们用一个用户-产品矩阵来描述用户对产品的喜好程度,那么协同过滤算法的目标就是填充缺失的元素,如下图所示。(These techniques aim to fill in the missing entries of a user-item association matrix)
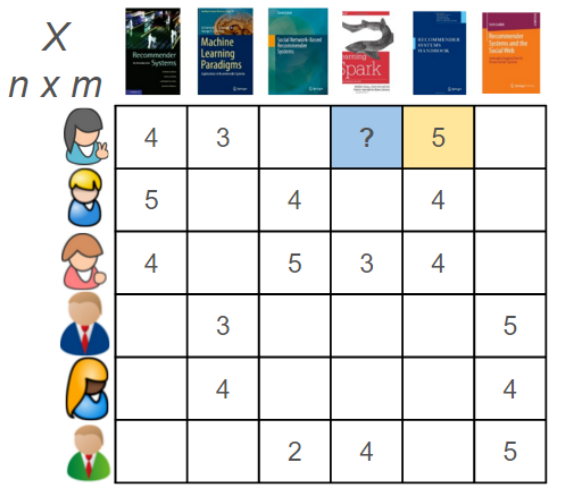
Spark.ml库中的推荐算法
spark.ml 库支持基于模型的协同过滤推荐推荐算法,其中用户和商品通过一小组隐语义因子(latent factors)进行表达,并且这些因子也用于预测缺失的元素。spark.ml库使用 ALS算法来学习这些隐性语义因子。
交替最小二乘法(ALS)
交替最小二乘法 (Alternating Least Squares,ALS)常用于基于矩阵分解的推荐系统中。
例如:将用户(user)对商品(item)的评分矩阵分解为两个矩阵:
- 一个是用户对商品隐含特征的偏好矩阵
- 另一个是商品所包含的隐含特征的矩阵。
在这个矩阵分解的过程中,评分缺失项得到了填充,也就是说我们可以基于这个填充的评分来给用户做商品推荐了。
隐性反馈(implicit feedback)和显性反馈(explicit feedback)
基于矩阵分解的协同过滤的标准方法一般将用户商品矩阵中的元素作为用户对商品的显性偏好。在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈(例如游览,点击,购买,喜欢,分享等等)
在 MLlib 中所用到的处理这种数据的方法来源于文献: Collaborative Filtering for Implicit Feedback Datasets。 本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分而是和所观察到的用户偏好强度关联了起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
使用关联规则做预测
在 Spark.ml 中,还有一种 Frequent Pattern Mining (FPM) 算法,这种算法用来计算物品之间的关联性。称为关联规则(Association Rule)。