Crash Course Computer Science(31-40)
P31 计算机安全
并不是所有人都在互联网和万维网上规规矩矩,计算机安全即是保护计算机的保密性、完整性和可用性。保密性 是指只有有权限的人才能读取计算机系统和数据,黑客盗取信用卡即是破坏保密性,完整性 是指只有有权限的人才能使用和修改系统和数据,黑客盗取邮箱密码冒充你就是破坏完整性,可用性 是指有权限的人应该随时可以访问系统和数据,拒绝服务攻击(DDOS) 是黑客发送大量虚假请求让网站崩溃,这破坏了可用性。
很多安全问题都可以归纳为2个问题:你是谁,你可以访问什么。为了区分谁是谁,我们用 身份认证(Authorization),常见的身份认证是用户名和密码,或密钥和令牌,以及生物识别(指纹、刷脸),这几种方式各有优缺点。认证之后,我们还需要对用户进行 访问控制,也叫 鉴权(Authentication),不同的用户在系统中拥有不同的权限,通常用权限控制列表来实现,常见的权限有读、写、执行,有一种权限控制原则叫 no read up、no write down。
即便做了最严谨的安全措施,还是不可避免地有被攻破的可能性。从另一角度出发,开发者应该用最少的代码、最少的权限实现功能,以防潜在的漏洞,除此之外,操作系统还会对程序进行隔离,程序只能访问操作系统分配给它的内存块,无法访问其他内存,一台计算机可以运行多个虚拟机,虚拟机之间也是互相隔离的。这样能一定程度防范安全攻击。
P32 黑客&攻击
黑客攻击最常见的方式不是通过技术,而是通过欺骗,这叫 社会工程学。一种常见的方法是钓鱼网站,使用假官网诱导你输入真实的账号密码,或者假装IT人员给你打电话诱导你泄露计算机信息。还有一种方法是植入木马,木马会伪装成人畜无害的软件,实际上是会窃取个人信息的有害软件。如果能物理接触计算机,有些黑客会用复制内存的方式,让输入错误等待机制失效。而如果只能通过互联网,早期黑客会使用缓冲区溢出的漏洞,覆盖掉重要的内存值,如 IS_ADMIN = TRUE,但现代的操作系统和程序已经让这种方式很难命中了。另一种经典的手段叫代码注入, 如 SQL 注入,在 SQL 语句中插入恶意语句。
如果有足够多的电脑被黑客控制,那么这些电脑叫做 蠕虫,可能会被用来做恶意的事,如群发垃圾邮件,挖矿,或发起DDOS攻击,
P33 加密
安全专家知道,不可能有 100% 安全的系统。所以计算机系统通常会部署多层防御。而 加密 就是极其重要的一层。把明文通过算法转成密文就叫加密(encryption),反之叫解密(decryption)。密码学早在计算机出现之前就有了,如战时德军的英格玛。在计算机出现后,早期应用最广泛的加密是1977年 IBM 和 NSA 开发的数据加密标准(DES),采用56位二进制,有大约72千万亿个不同的密钥,到了1999年计算机能力提升,有计算机两天内就能穷举所有可能的密钥,所以DES不再安全。2001年,出现了更高级的 AES 算法,有128位/192位/256位,128位的密钥哪怕用如今所有的计算机,也要算个上万亿年。
加密和解密依赖于相同的密钥,但我们要如何让对方知道密钥呢?解决办法是 密钥交换,密钥交换是一种不发送密钥,但依然让两台计算机在密钥上达成共识的算法,就像把多种颜色混在一起很容易,但看一种颜色很难知道是哪几种颜色混合而成的。在数学上,可以用单向函数来实现。如果双方用一样的密钥加密和解密信息,就叫 对称加密,DES、AES都是对称加密的。
还有一种加密叫做 非对称加密,一个公钥,一个私钥,用公钥加密信息,只有私钥才能解密。换句话说,知道公钥只能加密而不能解密。或者反过来,用私钥加密,只有公钥才能解密,这种方法通常用来做签名,例如服务器做了加密,客户端如果能解密,说明数据来自正确的服务器。如今,最流行的非对称加密技术是RSA。
P34 机器学习&人工智能
决策树 & 支持向量机
计算机很擅长收集数据,处理数据,但如果我们想根据数据来做决定怎么办?我们希望计算机从数据中学习,然后自行做出预测和决定,这就是 机器学习 的本质,机器学习是实现人工智能的技术之一。在一系列数据中做出区分和判断,称为 分类,分类的算法称为 分类器,很多算法会把数据简化成 特征,特征是用来帮助分类的值。我们会给计算机提供一些已知的标记数据,记录了特征值和种类,特征的边界点叫做 决策边界,我们会用一个混淆矩阵来记录正确的分类和错误的分类,机器学习算法的目标就是最大化正确分类,最小化错误分类。当我们遇到一个未知的数据,我们可以测量它的特征,根据决策边界判定它属于哪一种数据。把决策空间划分成一块一块的简单方法,叫做 决策树。生成决策树的机器学习算法,需要选择用什么特征来分类,每个特征用什么值。如今,有些机器学习算法会用到多个决策树,叫做 决策森林。
也有一种不用决策树的算法,叫做 支持向量机,它是用任意曲线来划分决策空间。只有两个特征的二维划分的可能比较简单,但特征一多,就不是一件容易的事情了。这也正是机器学习的价值所在。

人工神经网络
决策树和支持向量机都是基于统计学的,但也有不是统计学的算法,其中最值得一提的是 人工神经网络,就像大脑里的神经元一样。神经网络的输入层接收多个输入,然后经过隐藏层,里面有多个神经元,每一个神经元经过加权、求和、偏置、激活函数等数学转换,最后输出层输出结果。其中,隐藏层可能有很多层,因此得名 深度学习。

深度学习算法非常复杂,但还不够“聪明”,因为一个算法只能做一件事情——分辨飞蛾种类、识别人脸、翻译、自动驾驶,这类人工智能称为 弱AI,而能够让计算机在空闲时创作音乐、找出美食食谱,就像人类一样聪明的,叫做 强AI,目前还很难实现。
AI不仅可以吸收大量信息,还可以不断自我学习,速度比人类还快得多,IBM的沃森吸收了2亿个网页的知识,在知识竞赛中碾压全人类,Google的 AlphaGo 不断跟自己的克隆版下围棋,发现成功的路径,最终战胜人类最强选手。这叫做 强化学习。
P35 计算机视觉
抽象是构建复杂系统的关键。
计算机科学家一直致力于让计算机“看懂”图像和视频,因此诞生了 计算机视觉 学科。
像素的颜色是由RGB值决定的,最简单的视觉定位方法是找到特定RGB值,然后逐层扫描图像,在视频的每一帧都跑这个算法,就可以追踪图像的移动。但是这种简单粗暴的方法并不适用于受光线、阴影等影响的现实场景,而且多个物体同种颜色会干扰算法。更进一步的算法是将图像分成一块块进行处理,例如9个像素为一块。物体边缘的颜色块往往跟背景有一定差异,专门识别这些边缘的算法叫做 核 或者 过滤器。将过滤器应用于一个块,计算出新像素值,这种操作叫做 卷积(convolution)。识别物体垂直边缘的过滤器如果应用在图片的所有像素,图片将会发生如下图的变化。

如果我们再叠加识别水平边缘的过滤器,就有了水平的白线。这样物体的边缘就出来了。不同的过滤器能识别不同的边缘,锐化、模糊、匹配特征。多个过滤器组装在一起成为窗口,早期人脸识别算法就是基于此开发出来的。时至今日,热门的算法是 卷积神经网络,通过神经网络深度学习的方式来做人脸识别,本质上是一堆过滤器卷积再卷积。
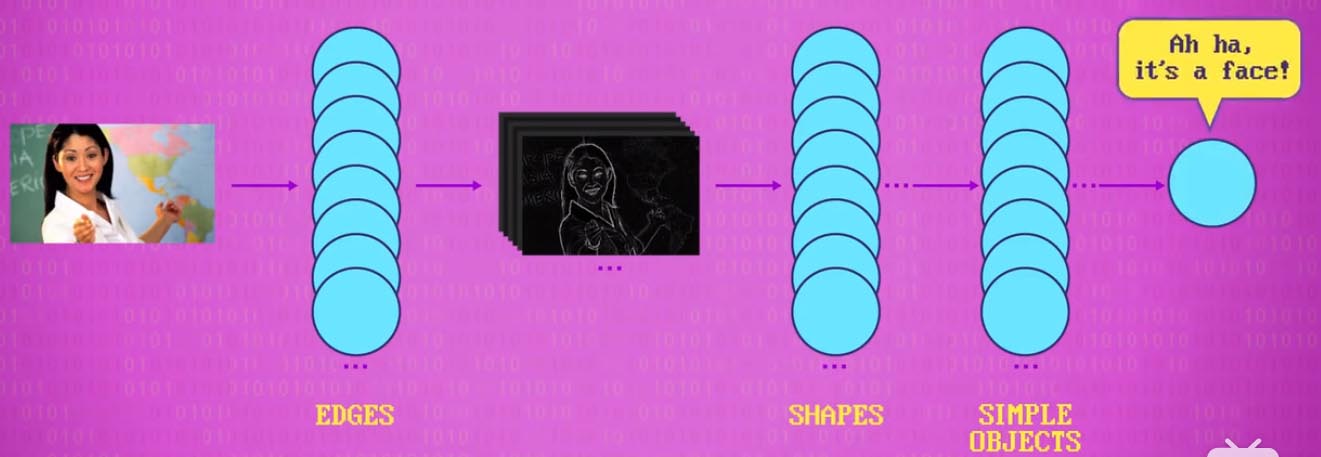
识别出人脸后,计算机会再用其他进一步的算法,来判断情感,是哭是笑,然后做出不同的响应。除人脸识别外,如今,计算机视觉被广泛用在商品条码扫描,无人驾驶汽车,照片滤镜。
P36 自然语言处理(NLP)
计算机科学家的目标不仅仅是让计算机看懂图像,还要听懂人话。于是有了计算机学科+语言学科的 自然语言处理(NLP)。
编程语言通常语法固定,稍有错误都会编译报错。但人类语言不确定因素很多,如语序、发音、口音等,只要不是很严重的错误,对方一般都能理解,这对计算机来说却很难。早期NPL研究怎么把句子分成一块块更容易处理,例如 冠词+名词+动词 等等各种组合,形成 分析树。语音搜索一般都是这样做出来的。
短语结构规则把语言结构化,用来生成句子。构造句子的成分如果放在信息网络上,就形成了知识图谱。计算机会根据既定事实处理、分析、生成文字,然后跟你聊天。早期聊天机器人用的是专家系统,即把可能的问题和对应的答案存在字典里,但这很难维护而且不适用于复杂的对话场景。如今,聊天机器人使用机器学习,用大量真人聊天数据来训练机器人,应用在智能客服上面。
计算机如何从声音中提取词汇?这属于 语音识别。以前都是用特定规则来做,如今大都切换到深度神经网络了。其中用到将波形转频率的算法,叫做 快速傅里叶变换(FFT)。频率里会有各种元音、音素的特征,当遇到相似单词,语音模型会根据语法规则和统计学方法,找到可能性最高的单词。
P37 机器人
机器人是由计算机控制,可以自动执行一系列动作的机器。第一台计算机控制的机器出现在1940年代,可以执行一连串指定的程序。精细的控制能让我们生产出之前很难做的物品。机器中用来判断位置的控制回路叫 负反馈回路,包含传感器、控制器、系统组件(泵、电机、加热元件)。在实际情况中,还要考虑外界环境影响,如摩擦力,风力,上下坡等,因此一般都用 PID控制器 来算误差和比例值,在汽车巡航控制,无人机等都被广泛应用。更高级的机器人一般有多个控制回路,用来保持各个数值的稳定,从而配合做出不同的动作。
机器人可以轻易做到精细的动作,但对人类来说很基础的动作,如双脚走路、摸狗等,对机器人却很难。如今,像 Google 等技术公司已经开始在用机器学习的方式训练机器人做人类动作,所以机器人早晚也能做到。最近几年,机器人最大的突破是无人驾驶汽车,汽车的输入其实很简单,转弯、加减速、刹车,难的是让汽车看懂路标和信号灯,指示牌,车流和行人等,因此得结合计算机视觉技术。
近年来又出现了一些类人类机器人,模仿人类的外观和行为,也是通过 机器人+计算机视觉+自然语言处理 实现的,只是目前还不够成熟。
P38 计算机心理学
计算机终究只是人类的工具,为了让人类使用得更愉快,设计者们甚至都运用了心理学的原理。
- 人类很擅长给颜色的深度排序,而不擅长给不同颜色排序。所以好的界面通常用颜色深浅度来排序连续的数据,用不同的颜色来区分不同的数据;
- 人类的短期记忆能记住5-9个物体,因此把信息分成小于5的块更容易理解,例如电话号码通常用 137-1111-1111 的方式;
- 程序的 直观功能 很重要,例如,平板用来推、旋钮用来转、插槽用来插,用户一眼就看懂怎么使用;
- 好找好记固然重要,但熟练使用之后人类会建立心理模型,因此好的界面应该提供多种方式来实现目标,例如复制可以在菜单栏找到,也可以直接 Ctrl+C
- 心理学研究表明,比起面对面,人们更愿意在互联网上透露自己的个人信息,因此问卷调查最好是用聊天机器人,而非虚拟真人助手。
- 说服、讲课或引起注意,需要用到眼神交流,这有助于加强参与感。但视频通话时摄像头往往不在眼睛注视的前方,因此有专门的软件算法来纠正偏差。
- 人机交互被用来感知人类的情绪,让计算机更好地应答。
计算机心理学带来的好处很多,但也会带来一些坏处,例如使用计算机利用人类心理诱导人类行为。但总而言之,计算机+心理学还有很多值得去挖掘的地方,这个方向也一直在发展。
P39 教育科技
计算机带来的改变之一是信息的创造和传播能力。互联网上大部分的信息是教育型信息,正如这门课的视频一样。但是网络视频带来的问题是,几百万人同时学一门视频课程,老师如何给几百万人打分?而且缺少学习互动和反馈。因此计算机教育科学家研究了智能辅导系统,通过建立模型来针对性辅导学习,通常是使用贝叶斯知识追踪让学习练习技能,直至掌握。甚至运用上百万学生学习、做题时的数据来做 教育数据挖掘。虚拟现实和增强现实技术也应用在教育科技上,帮助学生直观体验学习。
人们甚至幻想,能不能通过教育科技,直接把知识下载到大脑呢?可谓脑洞大开。
P40 计算机的未来
说到计算机的未来,很多人想到的是 人工智能,科技无处不在,如影随形。有一句话叫最好的科技是让你感受不到科技的存在。然而,就像有了灯泡之后,蜡烛也依然存在,并不是所有的地方都会用到AI,或需要AI,最可能的情况是AI成为人类科学家的好工具。
真正让人担忧的是,人工智能是否会超越人类智能?按照AI现在的发展速度,几十年内计算机的能力就会超过人类。智能科技的失控性发展叫做 奇点。一旦奇点到来,首先AI会替代掉大部分重复性劳动的工作,许多人将会失业,其次也可能会影响人的身体(例如脑电接口)……
总之,未来是不可预测的,但也不必太过悲观。许多的新技术正在诞生,至少目前来看,人类的生活因为计算机正变得越来越好,不是吗?
