Crash Course Computer Science(11-20)
P11 编程语言发展史
一条计算机指令,00101110,前四位是操作码,表示 LOAD_A(把值从内存复制到寄存器A),后四位是内存地址14,简写为 LOAD_A 14,意思是,读内存地址14,复制到寄存器A。计算机只认识二进制数,用二进制指令编写的程序称为 机器语言。早期人们编程的方式,是先在纸上写英文版的程序,再根据操作码表制作成二进制码的纸带,丢到计算机去处理。像这样,对计算机程序进行高层次的描述称为 伪代码。
与其用机器码编写程序,为什么我们不直接写 LOAD_A 14 来表示 00101110,而中间翻译的部分交给机器去做呢?于是程序员发明了一种能将像 LOAD_A 14 这样的文字指令翻译成 00101110 这样的二进制指令的程序,叫做 汇编器(assembler)。用像 LOAD_A 14 这样的文字指令编写的程序,叫做 汇编语言。
1940-1950年代,一名美国海军军官,也是哈佛1号计算机的设计者 Hopper,她想到能否把一条自然语句翻译成多条汇编指令或机器指令,于是设计了一种机器叫做 编译器(compiler),专门把高级语言转换成低级语言。在高级语言里,我们用 变量 来抽象内存地址和值,程序员不必了解底层细节,从此,编程开始变得简单起来。
Hopper 一开始发明了一种 A-0 高级语言,但没有流行开来,反倒是1957年IBM发明的 FORTRAN 主宰了早期的计算机编程,但只能运行在IBM的机器上,再后来出现了所有机器都可运行的 COBLE,再后来出现了我们熟悉的C、C++、Objective-C、Python、Java、Golang等高级语言。
FORTRAN 项目总监 John Backus:
我做的大部分工作是因为懒,我不喜欢写程序,所以我写这门语言,让编程更容易。
P12 编程原理 - 语句和函数
a = 5 这是高级语言 Python 中的语句,意思是把值5赋给变量a,这叫做 赋值语句,也是初始化语句。if 、while 和 for 是常见的 控制流语句,表示条件判断和循环。高级编程语言都是通过特定的语句和语法组织起来的,跟英语、中文等自然语言没有本质不同。
当程序中有一部分代码在很多地方都要重复使用时,我们可以把它抽出来作为 函数。函数有参数和返回值,任何调用它的地方都能执行这段代码。下面是 Python 计算一个数的平方的函数:
1 | def pow(x): |
函数有助于模块化编程,帮助团队协作写出大型的程序。现代编程语言中,很多语言已经提前写好了一些常用的函数集合,叫做 **库(libraries)**。
P13 算法入门
解决问题的步骤,称为 算法。不同的算法可能得出相同的结果,但有些效率更高。
排序和算法的复杂度
排序 是一种常见的算法需求,选择排序 是一种最简单的排序算法。其思想是,从第一个数开始,找到数组中最小的一个数,跟第一个数交换,然后从第二个数开始,找到数组剩下的数字中最小的一个,跟第二个数交换,以此类推。下面是 Python 选择排序的实现:
1 | def select_sort(arr): |
可以看到,选择排序用了两个 for 循环,如果循环一次需要 n 个步骤,那么两个 for 循环大概需要 n * n 个步骤。 算法的输入大小和运行步骤之间的关系,叫做算法的复杂度。计算机科学家把算法复杂度描述为 大O表示法。需要 n * n 个步骤的算法,记为 O(n*n)。如果一个步骤需要1秒,当 n 为 8,这个算法需要 8 * 8 = 64 秒,当 n 为 80 ,这个算法需要 80 * 80 = 6400 秒,n增大了10倍,时间却增加了100倍,可见 O(n*n) 是呈指数级增长的,是一种效率很低的算法。
一种效率比较高的排序算法是 归并排序。它通过分治的思想,把一个大数组一分为二,分开的两个小数组又分别再一分为二,一直分到每个小数组都只有两个元素,排完序,再向上归并起来。这种算法的复杂度为 O(n*logn),n是需要比较的次数,logn是合并步骤的次数,例如,在有8个元素的数组中,有8个数需要比较,所以n是8,从2合并到4再合并到8,需要3次,也就是 log8=3。 O(n*logn) 呈对数级增长,效率比较高。
图搜索
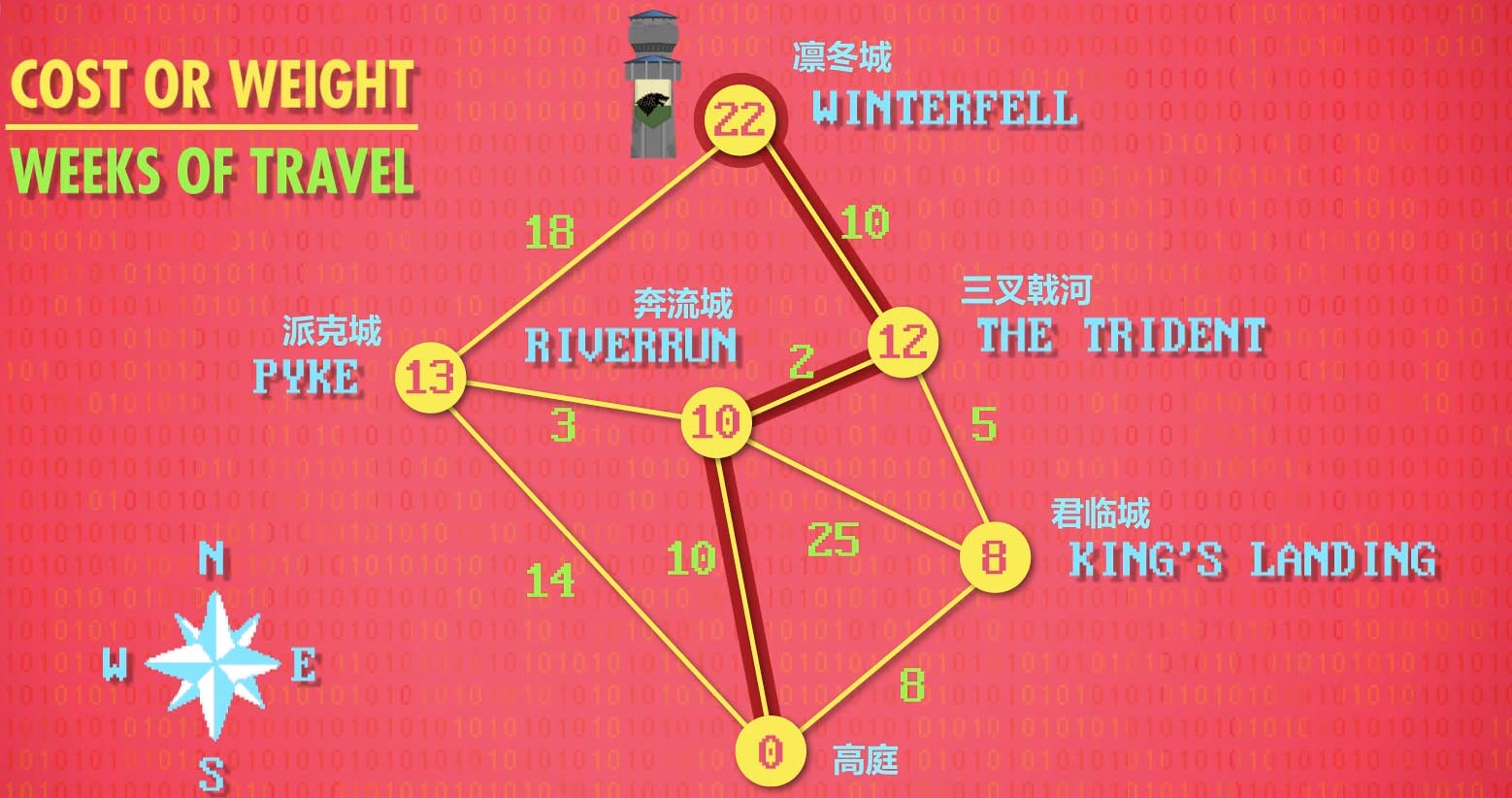
图搜索是另一种算法,图是一种用线连起来的一堆节点,从一个节点到另一个节点有不同的成本,称为 权重。如何用最少的成本,从一个节点到达另一个不相邻的节点呢?最简单粗暴的方法是把所有可能的走法都列出来,但这样的复杂度是 O(n!),比 O(n*n) 还糟糕。解决这个问题的一个经典算法是一位理论计算机科学家 Edsger Dijkstra 发明的,因此称为 Dijkstra 算法,他会从开始节点向相邻节点走,并记录每个节点的成本,到达下一个节点后,再继续向相邻的节点走,记录第一步跟第二步的成本和,一直到目标节点,找出成本最小的一条路径。
P14 数据结构
算法处理的是数据,然而在内存中,数据有多种存法。数据结构化存储的方式,称为 数据结构。
数组
一种简单的数据结构是 数组(array),或者叫向量(vecror)、列表(list)。定义数组时,需要先申请固定的内存空间,数据在内存中是连续存储的,通过下标(index)来获取对应的值。字符串本质上是字符数组,其最后一位是 zero,表示字符串结束。如果数组里面的每一个元素也都是数组,这样的数组称为 二维数组 或 矩阵(matrix)。因为数组在内存中连续存储,所以遍历很快,但从中间插入元素需要把后面的元素都相应地往后移动,因此插入效率不高,而且,数组的容量是事先定义好的,不能动态扩容。
结构体
把不同的数据类型打包在一起,叫做一个 **结构体(struct)**,例如要表示坐标,需要 x 和 y,就可以把它定义成一个 Point 结构体:
1 | typedef struct { |
链表
一种很有用的结构体叫做 节点(node),节点包含一个变量值,以及指向下一个值的指针。
1 | struct node{ |
一个节点有一个指针指向另一个节点,这样的数据结构叫做 链表(linked list),链表在内存中是不连续的,通过指针来指向下一个元素的位置,所以插入很快,但遍历比较慢,跟数组相反。链表理论上可以存无限节点,无需事先申请一片固定的内存区域。
栈和队列
栈(stack)和队列(queue)通常用链表来实现,当然也可以用数组。栈是一种后进先出(LIFO)的数据结构,而队列是先进先出(FIFO)的,跟栈相反。
树和图
链表只指向下一个节点(双向链表除外),如果我们在节点中再加多一个指针,像这样一个节点指向两个子节点的数据结构,叫做 二叉树。当然,我们也可以指向多个子节点,但前提是节点之间有固定方向,这叫做 树。树是一种很有用的数据结构,可以用在文件系统中,或者大规模数据的索引。著名的开源数据库MySQL的默认引擎InnoDB就是用二叉搜索树(B+树)作为索引的。
1 | struct node{ |
如果节点可以有任意个指向其他节点的指针,且方向不受约束,那这个数据结构叫做 图。上面提到的图搜索算法就需要用到图结构。
P15 艾伦·图灵
艾伦·图灵被誉为计算机科学之父,1912年出生于英国伦敦。他在剑桥读硕士期间,开始解决一个“可判定性问题”——是否存在一种算法,输入正式逻辑语句,输出准确的是或否。1935年美国数学家丘奇发明了 lambda算子 的数学表达系统,证明了这样的算法不存在,但其中的数学技巧太过于难理解。与此同时,图灵自己想了一种方法来解决这个问题,他提出了一种我们现在叫 图灵机 的假想计算机。包含了读写端、规则、状态和处理。他证明了这种计算机如果有足够的时间和内存,就可以执行任何的计算,这种强大之处称为 图灵完备。他利用图灵机模拟了 停机问题,证明了并不是所有的问题都可以用计算来解决。

丘奇和图灵证明了计算是有极限的,不是所有的问题都可以通过计算机来解决。1936-1938年,图灵在丘奇的指导下完成了博士学习,后来回到英国,1939年英国卷入第二次世界大战,图灵一直致力于破译德军密码的工作。战后,图灵回到学术界为许多早期计算机工作做出贡献,包括人工智能。1950年,图灵设想未来的计算机会跟人类难以区分,如果计算机能欺骗人类让人类以为计算机是人类,那才叫智能。这种测试,现在叫做 图灵测试,一个例子就是网页上的验证码。
1952年,图灵因性取向问题被当局认定为态度不端,强制他接受激素压制性欲,然而激素影响了他的性格和情绪,1954年图灵服毒自杀,年仅41岁。后人为了纪念他,很多东西以他的名字命名,包括计算机科学的“诺贝尔奖”——图灵奖。
P16 软件工程
面向对象
微软的 Office 软件大约有4000万行代码,20多万个函数,需要一整个部门合作完成。如何高效协作完成大型软件即是 软件工程(Software Engineering) 要考虑的问题。我们知道,代码块可以封装成函数,事实上,若干相关的函数还可以封装成 对象(Object),对象也是可以复用的。对象与对象之间可以有父子继承关系。像这样,将函数和变量打包成对象的思想,叫做 面向对象编程(Object-Oriented Programming)。
API
在软件工程中,不同的模块由不同的团队完成,他们需要约定相同的接口,叫做 程序编程接口(API)。API控制哪些函数让外部使用,哪些只能内部使用。在面向对象编程中,函数可以指定 private、public 等访问权限。
IDE
无论大型还是小型的软件,在编译前都只是一堆文字而已,你当然可以用记事本来写这些代码。然而,现代程序员基本上都会用专门的开发工具,封装了编辑器、调试、运行等等工具集的软件,叫做 集成开发环境(IDE)。
文档
软件还需要写文档来说明软件的用途和用法,一般文档都会写在一个叫做 README.MD 的文件里。当然,也可以直接写在源代码里,大部分语言用 // 或 /**/ 作为注释标记。
版本控制
合作开发的项目,会把代码放在代码仓库里,程序员想改其中的一段,需要先 checkout ,然后进行修改、测试,改完之后,再提交( commit)回代码仓库。源代码管理软件还会记录是谁改动了代码,如果有bug还可以回滚到之前的版本。

测试
编码与测试密不可分,测试可以统称为 质量保证测试(QA),主要是找 bugs。测试对确保软件质量至关重要。beta版本的软件意思是软件接近完成,但没有100%完全测试,而alpha版本的软件通常未经测试,可能存在较多 bugs。而 release 版,即是稳定发布版本了。
P17 集成电路&摩尔定律
软件的快速发展依赖于硬件的进步。早期计算机都是把独立元件用电线连接起来(想象一堆晶体管和成千上万条电线),随着复杂性的提高,计算机变得越来越庞大。与其如此,为何不把多个组件封装在一起,成为一个新的组件呢?于是,集成电路(Integrated Circuits, CI) 诞生了。1959年仙童半导体公司的 Noyce 使用硅来做集成电路,开创了电子时代,创造了 硅谷。之后,工程师们又发明了 **印刷电路板(PCB)**,器件变得更小、更便宜、更可靠。然而在微小的器件上连接电路是一件很难的事情,于是又有了 光刻 技术,光刻操作简单,又能制作出复杂的电路。

光刻的发展使晶体管变小,密度变高,1965年,戈登·摩尔看到了趋势:每18个月集成电路里面同样的空间能塞下的晶体管数量就会翻一倍。这就是 摩尔定律。1968年,诺伊斯和摩尔成立了一家新公司—— Intel(英特尔),如今已经成为世界上最大的芯片制造商。

50多年来,摩尔定律一直没有被打破,然而集成电路的精度已经快到达极限了,加上晶体管非常小,电极之间可能出现量子隧穿效应,这对集成电路的发展又提出了新的挑战。
P18 操作系统
操作系统(Operating System,OS) 也是一种程序,它具有操作硬件的权限,并且可以运行和管理其他程序。最开始,计算机一次只能运行一个软件,有了操作系统之后,可以让计算机一个接一个地运行软件,不用手工处理,这叫 批处理。早期的程序直接运行在硬件上,需要适配不同的机器,有了操作系统以后,操作系统提供统一的硬件抽象,叫 设备驱动程序,上层应用直接跟驱动打交道即可,屏蔽了底层硬件细节。
1962年,英国曼切斯特大学研发了一台超级计算机Atlas,拥有具备调度功能的操作系统。因为他们发现,程序的时间都耗费在IO上了,例如打印一份文档要5分钟,CPU可能1秒就执行完了,剩下的时间都只是在等待打印机结果,这段时间里,操作系统可以休眠这个程序,转而去运行其他程序,当打印机打印结束,再唤醒这个程序,继续后面的步骤。这样,多个任务共享单一的CPU,由操作系统来调度,这种能力叫 多任务处理。
有了多任务后,多个程序共享内存,操作系统会给每个程序分配独立的内存空间,但这样会带来碎片化的问题,解决办法是 虚拟内存。操作系统会在物理内存和虚拟内存之间做映射,好让程序以为它申请的内存是连续的。这种机制使得程序的内存可以动态增减,叫做 动态内存分配,同时也可以做 内存保护。
1970年代,计算机不仅可以多任务,还可以多用户,每个用户通过 终端 连接到计算机,为了防止某个用户占满计算机资源,每个用户只能使用小百分比的计算机资源,这叫 分时操作系统。早期分时操作系统中,最有影响力的是 Multics,但它被过度设计,系统本身占了一半以上的内存,于是,Multics 的开发者 Dennis 和 Ken Thompson 联手又打造了一个新的操作系统——Unix,Unix把系统分成了内核和工具两部分,使得核心功能大大精简,受到了很多人的欢迎,在80年代的PC中也逐渐流行开来。

后来操作系统逐渐发展,出现了像 Windows、Mac、Android、iOS 等我们熟悉的现代操作系统。
P19 内存&存储介质
内存(memory) 是易失性(volatile)的,断电数据即丢,存储(storage) 是非易失性(non-volatile)的,断电数据还在。
最早是用纸带和纸卡来存储临时数据,然而纸带打孔无法复原。工程师建造 ENIAC 时发明了延迟线存储器来存储数据。原理是在水银管一头接扬声器,声波在水银管中变成压力波,有波表示1,否则表示0,另一头接麦克风把声波转回电信号,再用电线首尾相连形成闭环。延迟线存储器一次只能读取一位,而且是顺序读取的,所以又叫 顺序存储器。
然而我们想要的是可以随时访问任意位置的存储器,即 随机存取存储器(random access memory,RAM)。1950年代,磁芯存储器 被发明,通过控制电流方向来反转磁性,从而存储1和0,很多磁芯圈串起来形成阵列,即可存储很多位,而且能随时访问任意位置。

后来又出现了更便宜、占空间更小的磁带,以及磁盘。磁盘由于很薄,可以把多个磁盘堆叠,磁头会上下滑动找到正确的盘再伸进去读数据。磁头找到正确的数据所用的时间叫做 寻道时间。软件和硬盘都是基于磁盘的原理制造出来的,在此就不再展开。值得一提的是,还有一种叫做光盘,也就是我们熟悉的CD、DVD,它的原理则不是磁性,而是通过挖坑造成光的反射不同来读取数据。
进入现代,内存和存储正朝着 固态(solid) 发展,固态是集成电路,而非机械结构,速度更快,体积更小,性能更好。
P20 文件系统
数据在内存或硬盘中是按一定格式存储的。最简单的文件格式是 .txt 文本格式,本质上是一堆二进制数,翻译成十进制数就是ASCII编码,ASCII编码映射成英文字符,呈现在屏幕上。.wav是存储音频格式的文件,也叫波形(wave)文件,文件开头会有一些 元数据,叫做文件头,记录了声音的码率、单声道或立体声等内容。存储图片(位图(bitmap))的文件格式是 .bmp,它也有元数据记录图像宽度、高度、颜色深度等,数据部分每3个字节记录RGB值,表示一个像素点。
为了存储多个文件,我们用 目录(directory) 来装载其他文件,目录本身也是一种特殊的文件。不仅仅存数据文件,还存了他们的元信息(创建时间、文件大小、长度等)。把文件目录化,以及管理所有目录和文件,就是 文件系统(file system)。现在的文件系统会把文件分成多个块,每个块预留一定空间以防文件增大,如果预留的也不够了,会在其它块里划分空间继续存这个文件。长此以往导致的结果是 文件碎片,可以用文件系统的碎片整理功能来解决。
文件删除只需要删除目录记录的元信息即可,数据本身不会被删除,直至被其他文件的数据覆盖。而文件移动,也只是在一个目录下删除元信息,在另一个目录下添加该元信息,数据本身并没有移动。