
用Python查成绩(二) 获取成绩
前言碎语
上一篇 用Python的requests库伪装成浏览器,模拟登录了学校的教务系统。登录进去之后,就可以开始做我们想做的事啦!
这一篇主要写写登录进去之后进入查询成绩页面,以及如何提取成绩信息。
访问查询成绩页面
构造URL
用Chrome F12工具可以看到,当我们进入教务系统,点击成绩查询按钮后,获取的URL是
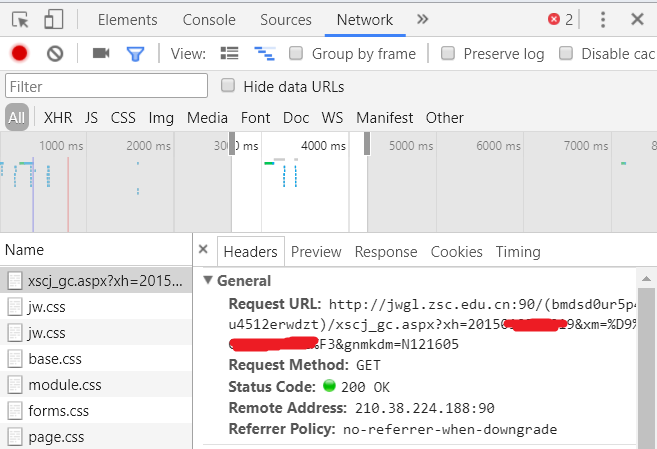
http://jwgl.zsc.edu.cn:90/(bmdsd0ur5p4fbu4512erwdzt)/xscj_gc.aspx?xh=2015XXXXXX9&xm=%D9%XXXXXF3&gnmkdm=N121605
其中2015XXXXXX9是学号,%D9%XXXXXF3是姓名的urlencode编码后的字符串
学号在前面已经输入过了,姓名字符串可以用urllib库
# student变量在上文中已经得到,即学生姓名
# number即上一篇输入过的学号
# student_name是姓名urlencode编码后的字符串
import urllib.parse
student_name = urllib.parse.quote(student.encode("gb2312"))
grade_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/xscj_gc.aspx?xh={}&xm={}&gnmkdm=N121605".format(number, student_name)这样就得到我们需要的URL
访问页面,获取网页源码
访问之前先更新一下cookie,然后get成绩页面获取网页源码
cookies = requests.utils.dict_from_cookiejar(s.cookies)
grade_headers.update(cookies)
response = session.get(grade_url, headers=grade_headers)构造post所需的数据
可以看到,要查询成绩,需要先选择学年和学期,然后点击下面不同的按钮
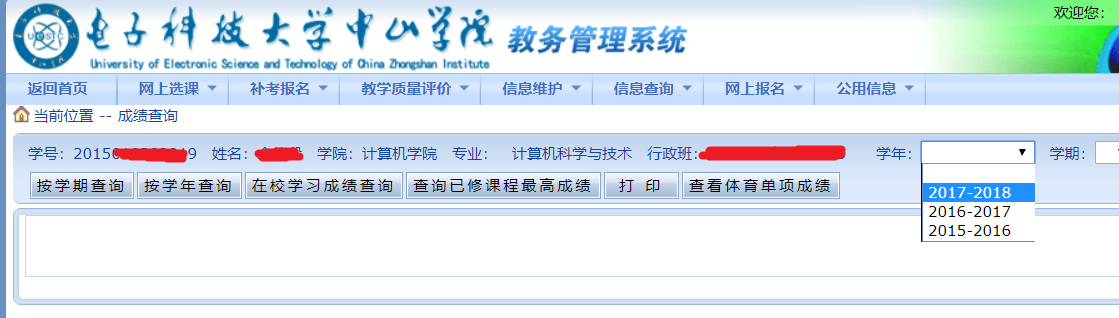
先随便点一个学年和学期,然后点击按学年查询,用F12工具追踪post数据

发现提交的数据包括一个新的__VIEWSTATE值,以及ddlXN、ddlXQ、Button5。不难猜测ddlXN是学年,ddlXQ是学期。至于Button5,其实是下面的“按学年查询”、“按学期查询”这些按钮。
我们刚刚已经用get方法访问了一次成绩查询页面,得到了其源码,因此在网页源码中可以直接找到新的__VIEWSTATE值,用etree和xpath提取出来。
然后构造post数据,再用post方法访问网页。
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="Form1"]/input/@value')[0]
# post 数据
data = {
"__VIEWSTATE": __VIEWSTATE,
"ddlXN": "2017-2018",
"ddlXQ": 1,
"Button5": u"按学年查询".encode('gb2312', 'replace'),
}
response = s.post(grade_url, headers=grade_headers, data=data)response是服务器返回给我们的网页,至此我们已经得到一个含有成绩信息的网页了。离成功不远了!
提取成绩
得到一个含有成绩信息的网页之后,分析其源码,看看网页中成绩是怎么显示的
<tr class="datelisthead">
<td>学年</td><td>学期</td><td>课程代码</td><td>课程名称</td><td>课程性质</td><td>课程归属</td><td>学分</td><td>绩点</td><td>平时成绩</td><td>期中成绩</td><td>期末成绩</td><td>实验成绩</td><td>成绩</td><td>辅修标记</td><td>补考成绩</td><td>重修成绩</td><td>学院名称</td><td>备注</td><td>重修标记</td><td>课程英文名称</td>
</tr><tr>
<td>2017-2018</td><td>1</td><td>10327540</td><td>linux 软件开发基础</td><td>必修课</td><td> </td><td>4.0</td><td> 3.91</td><td>90</td><td> </td><td>94</td><td> </td><td>93</td><td>0</td><td> </td><td> </td><td>计算机学院</td><td> </td><td>0</td><td></td>
</tr><tr class="alt">
<td>2017-2018</td><td>1</td><td>10302530</td><td>多媒体技术基础</td><td>限选课</td><td> </td><td>3.0</td><td> 3.39</td><td>59</td><td> </td><td>92</td><td> </td><td>82</td><td>0</td><td> </td><td> </td><td>计算机学院</td><td> </td><td>0</td><td></td>
</tr><tr>
<td>2017-2018</td><td>1</td><td>10337040</td><td>嵌入式网络协议及应用开发</td><td>限选课</td><td> </td><td>4.0</td><td> 3.88</td><td>93</td><td> </td><td>91</td><td> </td><td>92</td><td>0</td><td> </td><td> </td><td>计算机学院</td><td> </td><td>0</td><td></td>
</tr><tr class="alt">
<td>2017-2018</td><td>1</td><td>10329020</td><td>嵌入式最小系统设计</td><td>必修课</td><td> </td><td>2.0</td><td> 4.00</td><td> </td><td> </td><td>100</td><td> </td><td>100</td><td>0</td><td> </td><td> </td><td>计算机学院</td><td> </td><td>0</td><td></td>
</tr>
</table>这种情况,可以先用Beautifulsoup库的find方法,找到所有的tr标签的内容,存到trs变量中。然后在每一行tr中,依次找到课程名字、学分、绩点、平时成绩、期末成绩、总评(每一行的第3个td是课程名字,第6个td是学分,以此类推...)。最后构建一个字典,把数据存进去。
具体实现如下:
def getGrade(response):
html = response.content.decode("gb2312")
soup = BeautifulSoup(html, "html5lib")
trs = soup.find(id="Datagrid1").findAll("tr")[1:]
Grades = []
for tr in trs:
tds = tr.findAll("td")
tds = tds[3:4] + tds[6:9] + tds[10:13:2]
oneGradeKeys = ["课程名字", "学分", "绩点", "平时成绩", "期末成绩", "总评"]
oneGradeValues = []
for td in tds:
s = td.string.replace(" ", "") # 去掉空格
s = "".join(s.split()) # 去掉 \xa0 ,\xa0 是不间断空白符
oneGradeValues.append(s)
oneGrade = dict((key, value) for key, value in zip(oneGradeKeys, oneGradeValues))
Grades.append(oneGrade)
return Grades
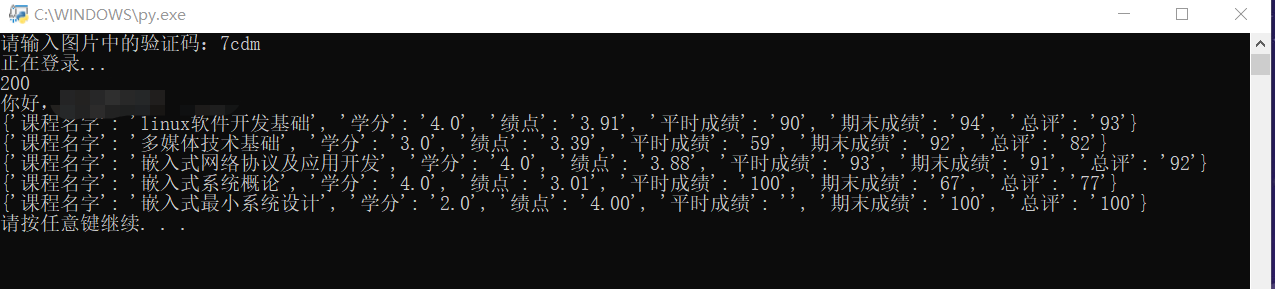
result = getGrade(response)
for go in result:
print(go)至此,成绩已经提取出来了。看看输出结果:
总结
这是我第一次做了一个像样的实用Python爬虫小项目,部分代码和成绩提取的内容参考了网上的代码。写得也不怎么样,不过最终还是实现了一开始的构想,已经很满足了。
参考链接:link
完整代码
# -*-coding:utf-8-*-
import os
import requests
from lxml import etree
from PIL import Image
from bs4 import BeautifulSoup
import urllib.parse
# 浏览器头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Host": "jwgl.zsc.edu.cn:90",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Upgrade-Insecure-Requests": "1"
}
# 验证码页面浏览器头
headers_code = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Host": "jwgl.zsc.edu.cn:90",
"Cache-Control": "max-age=0"
}
# 成绩页面浏览器头
grade_headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Host": "jwgl.zsc.edu.cn:90",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Upgrade-Insecure-Requests": "1"
}
def login_jcgl(session):
global number
number = input('请输入学号:')
password = input("请输入密码:")
url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx"
response = session.get(url)
# 把cookie转变成字典类型,并加入到header中
cookies = requests.utils.dict_from_cookiejar(s.cookies)
headers.update(cookies)
headers_code.update(cookies)
# Download checkcode
check_code_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/CheckCode.aspx"
pic_response = session.get(check_code_url, headers=headers_code).content
with open('ver_pic.jpg', 'wb') as f:
f.write(pic_response)
# open checkcode
image = Image.open('{}\\ver_pic.jpg'.format(os.getcwd()))
image.show()
# VIEWSTATE 教务系统 post 需要用到的一个随机值
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="form1"]/input/@value')[0]
# post 数据
data = {
'txtSecretCode': str(input('请输入图片中的验证码:')),
'txtUserName': str(number),
'Textbox1': '',
'TextBox2': str(password),
'__VIEWSTATE': __VIEWSTATE,
'RadioButtonList1': u"学生".encode('gb2312', 'replace'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': ''
}
# 登录教务系统
response = s.post(url, data=data, headers=headers)
print("正在登录...")
print(response.status_code)
if "验证码不正确" in response.text:
print("验证码不正确")
return login_jcgl(s)
if ("密码错误" or "密码不能为空") in response.text:
print("密码错误")
return login_jcgl(s)
if ("用户名不能为空" or "用户名不存在或未按照要求参加教学活动") in response.text:
print("学号错误")
return login_jcgl(s)
else:
print("登录成功!")
global student
student = getInfor(response, '//*[@id="xhxm"]/text()').replace("同学", "")
# student = student.replace("同学","")
print("你好," + student + " " + number)
return response
# 获取基本信息(用于验证是否登录成功)
def getInfor(response, xpath):
content = response.content.decode('gb2312') # 网页源码是gb2312要先解码
selector = etree.HTML(content)
infor = selector.xpath(xpath)[0]
return infor
def login_grade(session):
student_name = urllib.parse.quote(student.encode("gb2312"))
grade_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/xscj_gc.aspx?xh={}&xm={}&gnmkdm=N121605".format(number, student_name)
cookies = requests.utils.dict_from_cookiejar(s.cookies)
grade_headers.update(cookies)
response = session.get(grade_url, headers=grade_headers)
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="Form1"]/input/@value')[0]
# post 数据
data = {
"__VIEWSTATE": __VIEWSTATE,
"ddlXN": "2017-2018",
"ddlXQ": 1,
"Button5": u"按学年查询".encode('gb2312', 'replace'),
}
response = s.post(grade_url, headers=grade_headers, data=data)
return response
def getGrade(response):
html = response.content.decode("gb2312")
soup = BeautifulSoup(html, "html5lib")
trs = soup.find(id="Datagrid1").findAll("tr")[1:]
Grades = []
for tr in trs:
tds = tr.findAll("td")
tds = tds[3:4] + tds[6:9] + tds[10:13:2] # 0 1 3 4 6 7 8 10 12
oneGradeKeys = ["课程名字", "学分", "绩点", "平时成绩", "期末成绩", "总评"]
oneGradeValues = []
for td in tds:
s = td.string.replace(" ", "") # 去掉空格
s = "".join(s.split()) # 去掉 \xa0 ,\xa0 是不间断空白符
oneGradeValues.append(s)
oneGrade = dict((key, value) for key, value in zip(oneGradeKeys, oneGradeValues))
Grades.append(oneGrade)
return Grades
s = requests.Session()
response = login_jcgl(s)
response = login_grade(s)
result = getGrade(response)
for go in result:
print(go)
os.system("pause")代码写得比较烂,请多批评指教。