
用Python查成绩(一) 模拟登录
前言碎语
这个小项目的起因是每到期末,成绩总是一科一科不定时地出,每天都要登录教务系统查询成绩页面看看成绩出了没,出了没?
于是乎,就想到能不能用Python爬虫模拟登录教务系统,一键获取本学期所有科目的成绩!当然,一开始是想放到后台不断地自动查询、获取,等成绩更新的时候自动推送Email或微信。但鉴于时间、难度、寒假安排...想想还是暂时先做个一键脚本吧。
Just do it !首先来看看教务系统长什么样
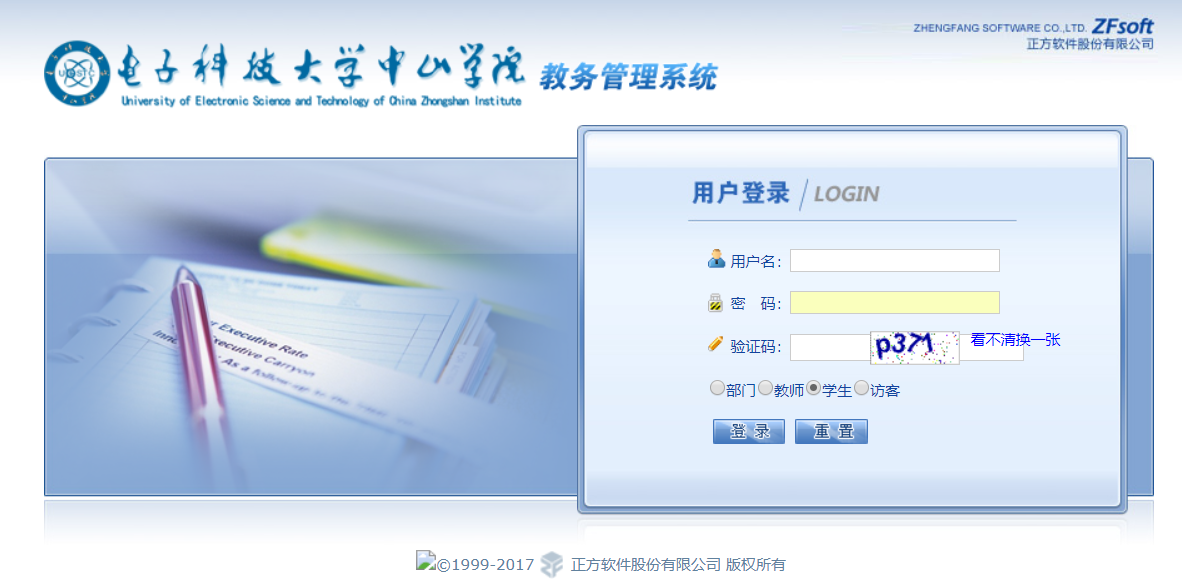
学校的教务系统是流行的正方教务管理系统,我们可以用 Python 的 requests 库来模拟登录。然后往方框里提交(post)正确的学号、密码和验证码,即可登录。
需要的储备知识:
- http协议
- python 3基本语法,request库的使用
- xpath和正则表达式
- cookie和session的功能和区别
建立会话
我们用requests每访问一个网页,都相当于一个全新的连接。比如我们登录了知乎,再点击知乎的编辑个人主页页面,如果单纯用requests去get,知乎的服务器会认为你没有登录,不能进入编辑页面,从而跳转到登录页面去。
而requests库的Session会话对象可以跨请求保持某些参数。意思就是你使用Session成功登录了某个网站,则在再次使用该Session对象访问该网站的其他网页都会默认使用该Session之前使用的cookie等参数。
用了Session后,之前登录的信息会保留下来,这样远程服务器就认为你已经登录,允许后续操作。
所以,我们首先实例化一个 Session对象。
import requests
s = requests.Session()查看header
根据 http 协议,我们每次请求一个网站都会带一个请求头,我们可以用Chrome的F12工具抓包查看请求头。然后用这个请求头把我们的Python代码伪装成浏览器。
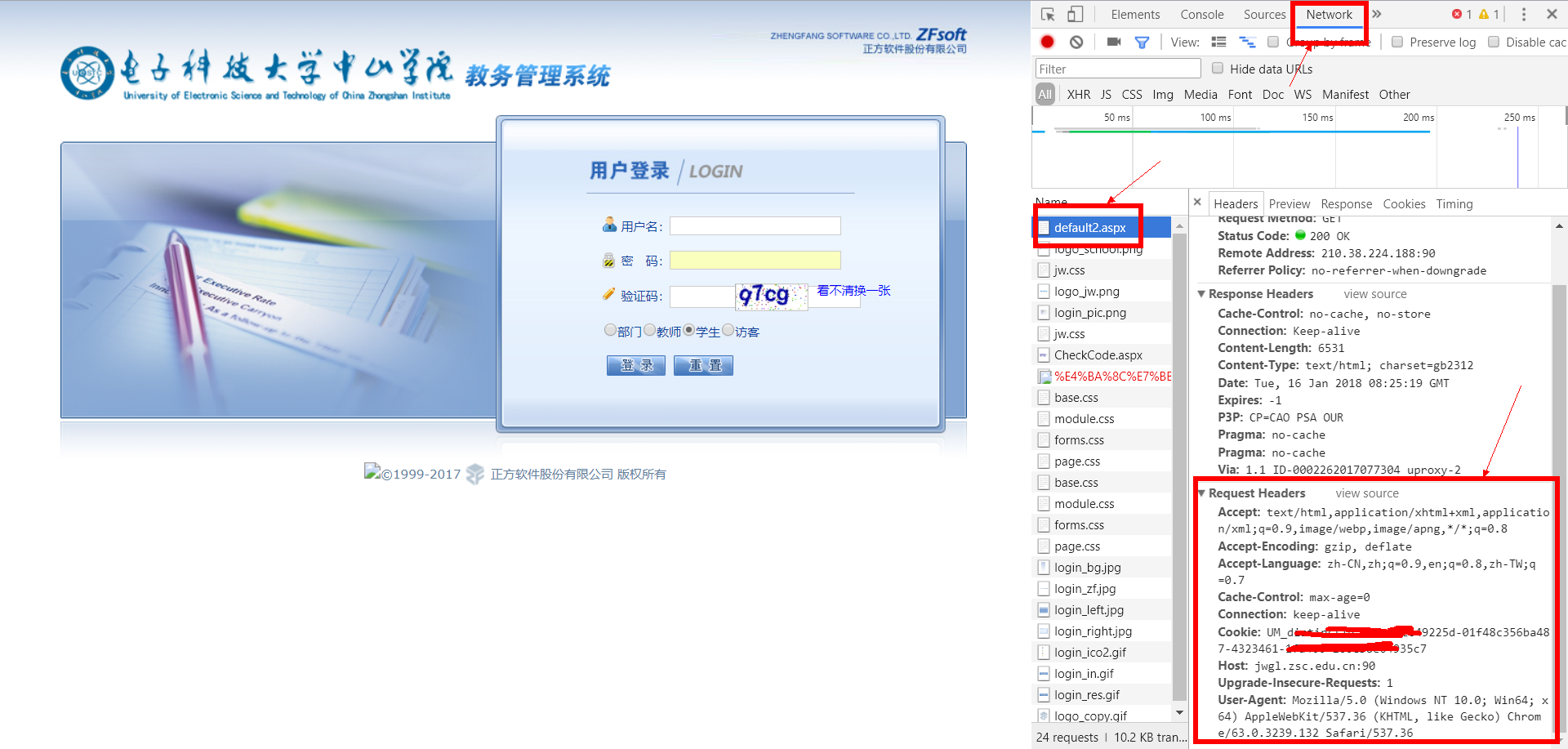
然后构造成字典:
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Host": "jwgl.zsc.edu.cn:90",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Upgrade-Insecure-Requests": "1"
}模拟登录
用request.Session访问教务系统
response是request.get返回的内容
number = input('请输入学号:')
password = input("请输入密码:")
url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx"
response = s.get(url)记录cookie, 并加入到header中
cookie的作用是让服务器记住你,所以我们也要把cookie加入到header中。但上面我们构造的header中不包括cookie,因为cookie是会变的,我们需要Session自动帮我们添加。
我们用requests的session方法保持cookie时,requests不能保持手动构建的cookie。原因是requests只能保持 cookiejar 类型的cookie,而我们手动构建的cookie(在header里面)是dict类型的。所以这里要做一个转换,然后把cookie加入到header里面去。
# 把cookie转变成字典类型,并加入到header中
cookies = requests.utils.dict_from_cookiejar(s.cookies)
headers.update(cookies)
headers_code.update(cookies)下载验证码并打开,手动输入验证码
验证码实际上也是一个链接,用F12找到链接是 http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/CheckCode.aspx
我们需要提前给它也设一个 header ,上面的headers_code.update(cookies)就是给验证码链接header加cookie的。
headers_code = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Host": "jwgl.zsc.edu.cn:90",
"Cache-Control": "max-age=0"
}然后需要用到Pillow库,它可以打开并显示本机图片。
from PIL import Image
import os
check_code_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/CheckCode.aspx"
pic_response = session.get(check_code_url, headers=headers_code).content
with open('ver_pic.jpg', 'wb') as f:
f.write(pic_response)
image = Image.open('{}\\ver_pic.jpg'.format(os.getcwd()))
image.show()构造post需要提交的数据
我们先随便在教务系统上输入一个错误的密码,然后用F12查看post的数据
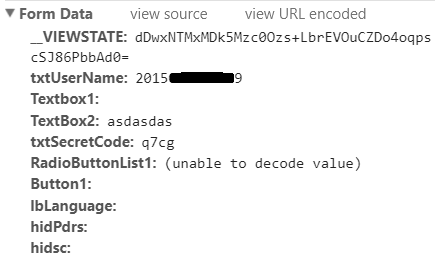
可以看到,post究竟提交了什么内容。
分析如下:
- VIEWSTATE:.net特有的一个特征码,可以在网页源码中找到并提取出来
- txtSecretCode:验证码
- txtUserName:学号
- TextBox2: 密码
- RadioButtonList1:实际上是网页中“学生”那个按钮
我们先用xpath提取VIEWSTATE的值
from lxml import etree
# VIEWSTATE 教务系统 post 需要用到的一个随机值
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="form1"]/input/@value')[0]然后构建post字典
# post 数据
data = {
'txtSecretCode': str(input('请输入图片中的验证码:')),
'txtUserName': str(number),
'Textbox1': '',
'TextBox2': str(password),
'__VIEWSTATE': __VIEWSTATE,
'RadioButtonList1': u"学生".encode('gb2312', 'replace'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': ''
}post登录教务系统
如果成功登录进教务系统,右上角会显示:欢迎您,XXX同学
因此可以从网页源码中获取到姓名
写一个获取基本信息的函数,传入网页的response和xpath查找规则,返回我们需要提取的信息。
def getInfor(response, xpath):
content = response.content.decode('gb2312') # 网页源码是gb2312要先解码
selector = etree.HTML(content)
infor = selector.xpath(xpath)[0]
return infor然后开始post,并加入错误判断
response = s.post(url, data=data, headers=headers)
print("正在登录...")
print(response.status_code)
if "验证码不正确" in response.text:
print("验证码不正确")
return login_jcgl(s)
if ("密码错误" or "密码不能为空") in response.text:
print("密码错误")
return login_jcgl(s)
if ("用户名不能为空" or "用户名不存在或未按照要求参加教学活动") in response.text:
print("学号错误")
return login_jcgl(s)
else:
print("登录成功!")
global student
student = getInfor(response, '//*[@id="xhxm"]/text()').replace("同学", "")
# student = student.replace("同学","")
print("你好," + student + " " + number)如果一切正常,输出应该为:
请输入图片中的验证码:nxgy
正在登录...
200
你好,(姓名+学号)这样我们就成功登录进教务系统了。
先写到这里,下一篇继续讲如何获取成绩。
完整代码
# -*-coding:utf-8-*-
import os
import requests
from lxml import etree
from PIL import Image
# 浏览器头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Host": "jwgl.zsc.edu.cn:90",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Upgrade-Insecure-Requests": "1"
}
# 验证码页面浏览器头
headers_code = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Referer": "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx",
"Host": "jwgl.zsc.edu.cn:90",
"Cache-Control": "max-age=0"
}
def login_jcgl(session):
global number
number = input('请输入学号:')
password = input("请输入密码:")
url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/default2.aspx"
response = session.get(url)
# 把cookie转变成字典类型,并加入到header中
cookies = requests.utils.dict_from_cookiejar(s.cookies)
headers.update(cookies)
headers_code.update(cookies)
# Download checkcode
check_code_url = "http://jwgl.zsc.edu.cn:90/(enfj1b45crtyfibn2cj2u045)/CheckCode.aspx"
pic_response = session.get(check_code_url, headers=headers_code).content
with open('ver_pic.jpg', 'wb') as f:
f.write(pic_response)
# open checkcode
image = Image.open('{}\\ver_pic.jpg'.format(os.getcwd()))
image.show()
# VIEWSTATE 教务系统 post 需要用到的一个随机值
selector = etree.HTML(response.content)
__VIEWSTATE = selector.xpath('//*[@id="form1"]/input/@value')[0]
# post 数据
data = {
'txtSecretCode': str(input('请输入图片中的验证码:')),
'txtUserName': str(number),
'Textbox1': '',
'TextBox2': str(password),
'__VIEWSTATE': __VIEWSTATE,
'RadioButtonList1': u"学生".encode('gb2312', 'replace'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': ''
}
# 登录教务系统
response = s.post(url, data=data, headers=headers)
print("正在登录...")
print(response.status_code)
if "验证码不正确" in response.text:
print("验证码不正确")
return login_jcgl(s)
if ("密码错误" or "密码不能为空") in response.text:
print("密码错误")
return login_jcgl(s)
if ("用户名不能为空" or "用户名不存在或未按照要求参加教学活动") in response.text:
print("学号错误")
return login_jcgl(s)
else:
print("登录成功!")
global student
student = getInfor(response, '//*[@id="xhxm"]/text()').replace("同学", "")
# student = student.replace("同学","")
print("你好," + student + " " + number)
return response
def getInfor(response, xpath):
content = response.content.decode('gb2312') # 网页源码是gb2312要先解码
selector = etree.HTML(content)
infor = selector.xpath(xpath)[0]
return infor
s = requests.Session()
response = login_jcgl(s)