
使用 Spark Streaming 进行实时流计算(二)
Spark Streaming 除了可以从三个基本数据源(文件、TCP套接字、RDD)读取数据,还能从高级的数据源中读取。这里的高级数据源,指的是 Kafka 或 Flume。
Kafka 简介
Kafka 是 LinkedIn 开发的一种高吞吐量的分布式发布订阅消息系统。 相比更擅长批量离线处理的 Flume 和 Scribe, Kafka 的优点是可以同时满足在线实时处理和批量离线处理。
Kafka 在很多公司的大数据平台中,通常扮演数据交换枢纽角色。Hadoop 生态系统中有很多的组件,每当有一种新的产品加入到企业的大数据生态系统中时,就要为这款产品开发与 Hadoop 各个组件的数据交换工具,显得比较麻烦。 而 Kafka,是一种通用工具,起到数据交换枢纽的作用。
不同的分布式系统(如关系数据库、流处理系统、批处理系统等)都可以统一接入 Kafka。
Kafka的核心概念
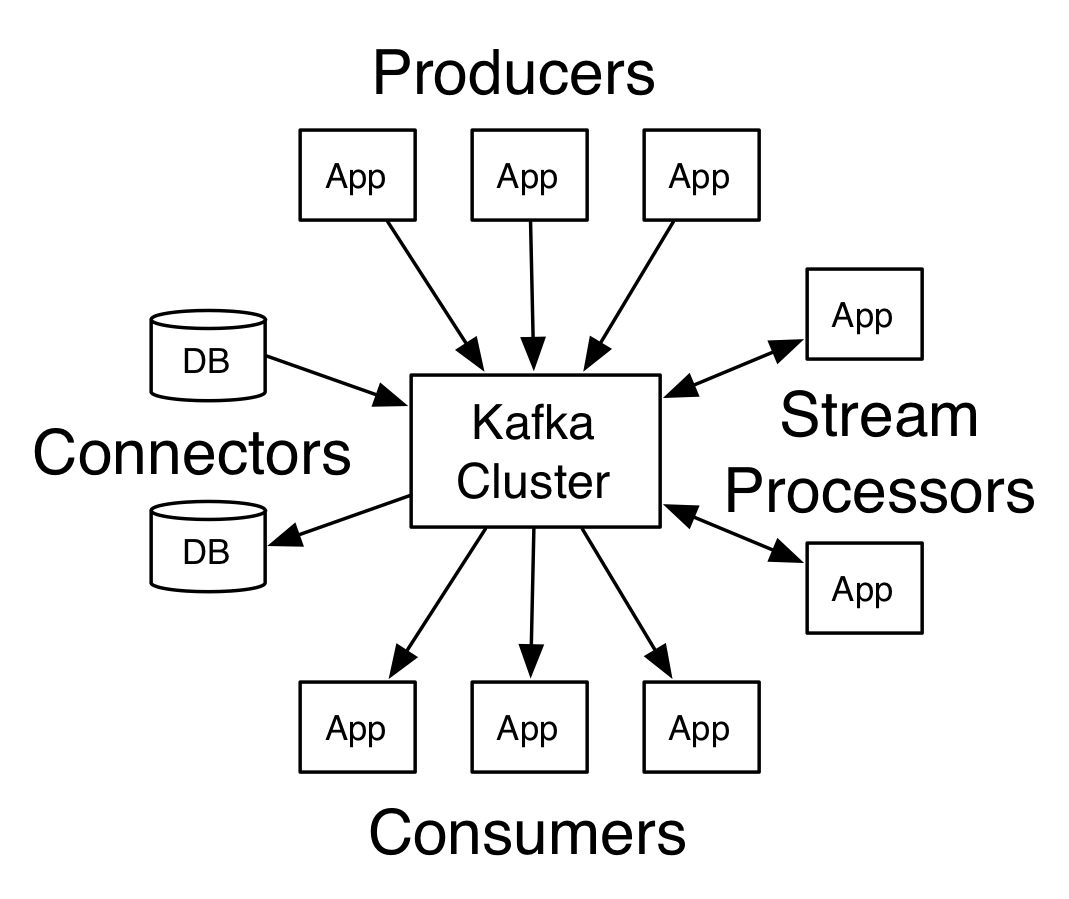
- Broker: Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic: 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition: Partition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer: 负责发布消息到Kafka broker
- Consumer: 消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group: 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
Kafka简单实例
- 安装完 Kafka 后, 会发现解压的 kafka 文件夹不是属于我的用户组, 修改所有者
sudo chown -R jerrysheh ./kafka- Kafka 是基于 zookeeper 的,因此首先要开启 zookeeper 服务
shell 1
bin/zookeeper-server-start.sh config/zookeeper.properties- 开启 kafka 服务
shell 2
bin/kafka-server-start.sh config/server.properties- topic是发布消息发布的 category , 现在以单节点的配置创建一个叫test的topic
shell 3
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test- 用
--list参数查看 topic 是否存在
shell 3
bin/kafka-topics.sh --list --zookeeper localhost:2181- 用 producer 生产一些数据
shell 3
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test随便输入点数据,比如
This is a message
This is another message- 用consumer来接收数据
shell 4
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning可以看到,刚刚我们用producer生产的数据,在shell 4 ,也就是consumer终端接收到了。
参考:官方文档
使用 Kafka 作为 DStream 数据源
放弃治疗